Spanner: Google’s Globally Distributed Database
总结
Spanner is Google’s scalable, multi-version, globally-distributed, and synchronously-replicated database. It is the first system to distribute data at global scale and support externally-consistent distributed transactions. This paper describes how Spanner is structured, its feature set, the rationale underlying various design decisions, and a novel time API that exposes clock uncertainty. This API and its implementation are critical to supporting external consistency and a variety of powerful features: non-blocking reads in the past, lock-free snapshot transactions, and atomic schema changes across all of Spanner.
Spanner是Google的可扩展,多版本,全球分布式和同步复制数据库。它是第一个在全球范围内分布数据并支持外部一致的分布式事务的系统。本文描述了Spanner的结构,其功能集,各种设计决策背后的原理,以及一个揭示时钟不确定性的新型时间API。这个API及其实现对于支持外部一致性和各种强大功能至关重要:在过去进行非阻塞读取,无锁快照交易,以及跨越所有Spanner的原子性模式更改。
- 是一个全球数据库, 数据分布到全球datacenter(能跨continents), 设计目标是支撑百万机器跨域数百个datacenter, 数据量支撑trillions of database row
- 通过paxos 来保证数据高可用
- 数据能自动做resharding, 当扩缩容或数据变化, failover时
技术概述
- 最早用户是F1, F1 使用5个副本, 一般情况下是一个地理region下3到5个datacenter, 这样能抗1~2个datacenter 灾难, 并且引用优先选择本地region
- 最开始的痛点来自bigtable:
- 复杂, 并持续演进的schema
- 强一致性在跨区域环境(低时延环境)
- 有一些尝试用megastore(300多个应用, 如gmail, picasa, calandar, android market, AppEngine), 尽管写吞吐比较查, 当支持半关系模型数据和支撑强同步
- 开始从bigtable 这样的kv store 进化而来, 支撑多版本的数据库
- 数据采用半结构化table
- 数据具备多版本, 每个版本以commit timestamp 标签
- 应用可以使用老的timestamp 进行获取老的版本
- 老的版本数据会由gc 策略来决定是否保留
- 支持参加事物模型
- 提供sql 查询语言
- percolator 的性能慢, 导致事务都在上层来处理, 从而提高性能
- 技术特点
- 数据的副本配置, 可以由应用动态调整, 并且以一定的细粒度
- 应用可以控制,
- 数据放到哪个datacenter,
- 数据距离user 多远,
- 每个副本之间的距离
- 有多少个副本
- 数据可以根据使用负载平衡透明并动态的从一个datacenter 挪到另外一个
- 事务2个能力(支持分布式)
- external consistent reads and writes
- 序列化顺序, 如果t1 比t2 commit 更早, 则t1 的timestamp 比t2 的timestamp 更小.
- 核心是TrueTime API
- 以一个timestamp 全局一致性读
- external consistent reads and writes
- 事务的能力保障了一致性backup, 一致性mapreduce 执行, 原子更新, 全球范围内, 甚至正在进行的事务中.
True Time
- true time api 直接暴露clock 的不确定性
- 如果clock 的不确定性太大, spanner 会slow down and wait uncertain.
- true time api 由cluster-managerment software 来提供并实现
- cluster-managerment software 的实现保障不确定性足够小, 一般不小于10ms. 通过使用多个现代时钟reference(gps和原子钟)
- 不确定性的保守report 对正确性很有必要, 并保持不确定区间小从而保障了性能.
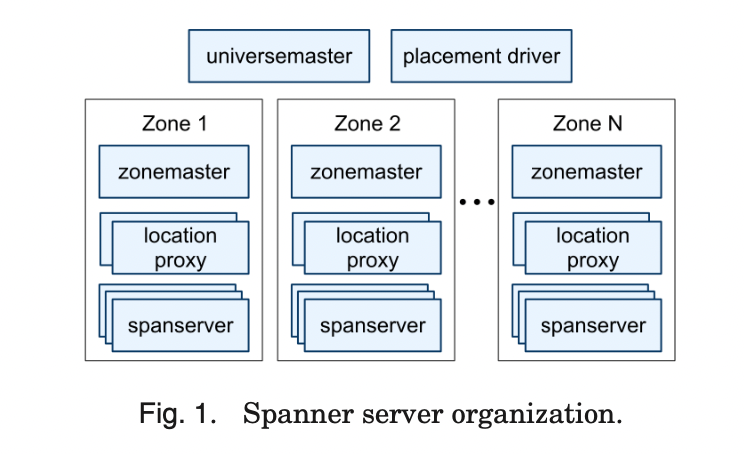
架构细节
数据搬迁, 副本, 数据locality的最小单元是direcotry
一个spanner的部署称为universe. (可以理解为一个universe 为一个spanner 集群)
spanner 集群由一组zone 来管理, 一个zone 是一批spanner的模拟组合. (非常类似ob)
可管理部署单元是zone, 可以添加一个zone(添加一个新的datacenter), 也可以减少一个zone(turn off 一些机器), zone 是物理isolation, 一个datacenter 可能含有一个或多个zone, 一个datacenter的不同组的机器可以组成不同的zone, 然后数据被分区到不同的zone里.
![Spanner: Google’s Globally Distributed Database]()
一个zone 有一个zonemaster和数以牵记的spannerserver. zonemaster 负责assign data 到spannerserver.
spannerserver 响应客户请求.
每个zone 有一批location proxy, 他们负责路由.
universe master 和placement driver 当前是单点.
universe master 展示所有zone的状态信息
placement driver 定期和spannerserver 通信, 确认哪些数据需要搬迁(满足负载均衡或升级副本限制), 搬迁的粒度是分钟级.
软件栈
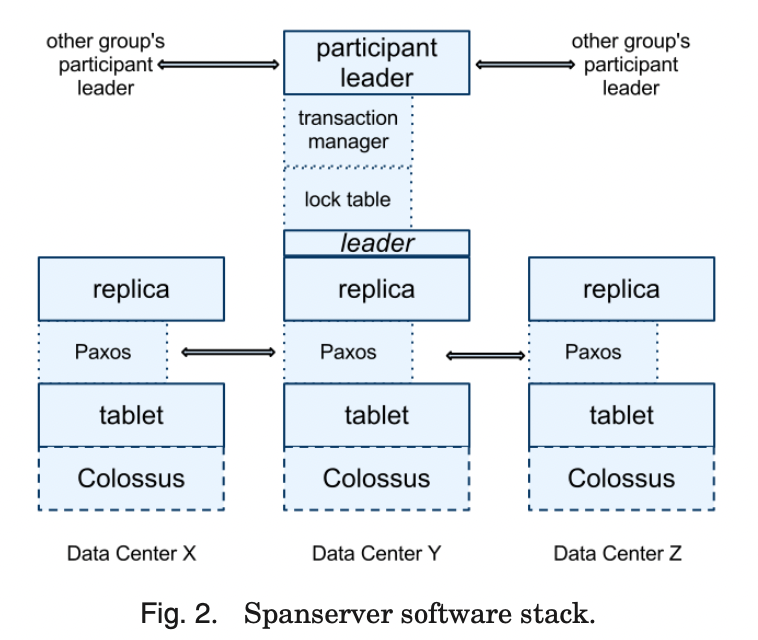
- 在底层, 每个spannerserver 负责100 到1000 个tablet 实例.
- tablet 类似bigtable tablet 的抽象. 可以理解为一批类似如下
- (key:string, timestamp:int64) –> string
- tablet 组织在类似b-tree的file 和wal 的日志中,
- 所有数据存在colossus这个分布式文件系统(gfs的继任者)
- 每个tablet 一个paxos group(最早一个tablet 多个paxos group), 每个
- 每个paxos state machine 把它的元数据和日志存到它的tablet中
- paxos 支持long-lived leader, leader 是基于时间的leader lease, 默认10s
- 每个log 实际上要写2次, 一次在tablet 的log, 另外一次在paxos log 中. (这是当前的权宜之计, 后续会彻底修正)
- paxos 是基于pipeline的, 因此会提升吞吐量. pipeline 基于Lamport “multi-decree parliament”, pipeline 摊平了leader 选举的代价以及在不同的裁定中允许并行投票. 尽管裁定(decree)允许乱序, 当实现中还是让裁定有序.
- paxos 实现了一致性的复制性的mapping(前述数据的mapping 方式), 每个副本的key-value mapping 存到它对应的tablet中.
- leader 发起paxos 协议写, 如果副本已经更新了, 可以直接读副本的底层tablet的state.
- 每个paxos group 的leader 来实现lock table 来实现并发控制(leader 的long live 是保障lock table 高效的关键手段). lock table 含2阶段locking,
- map key的范围到lock 状态
- 当冲突时, 在优化并发控制下, 长事务慢慢执行
- 要求同步的操作如事务读, 需要申请lock table 的lock, 其他操作bypass lock table.
- lock table的状态是volatile
- 每个paxos group 的leader实现事务manager来支持分布式事务.
- 事务manager 用于实现 参与leader(participant leader), 其他为参与slave
- 如果一个事务只涉及一个paxos group, 它会bypass 事务manager, lock table和paxos 可以提供事务能力
- 如果一个事务涉及多个paxos group, paxos group的leader 会执行2阶段提交. 其中之一的leader 会被选举为协调者, 那个paxos group的其他成员为协调slave.
- 每一个事务manager的状态也是用paxos group 存储下来的.
- 数据搬迁, 副本, 数据locality的最小单元是direcotry (更好的称呼应该为bucket)
- directory 是一段连续的key, 贡献一个公共的prefix
- 应用可以控制这批数据的locality, 可以通过小心选择key
- dirctory下的数据拥有相同副本配置.
- directory 可以在不同的paxos group 之间迁移
- 常常因为让数据更靠近访问者而进行搬迁
- 一个50MB 的direcoty 几秒就可以搬迁万
- 一个paxos group 包含多个directory
- paxos group 并不是row space 一段字段序连续的partition
- 实际上一个tablet 是包含多个row space partition的container, 方便多个directory 被关联访问.
- 如果directory 如果增长非常大, 会把directory 分成fragments, 搬迁粒度会以fragment拉完成
- movedir 是一个后台任务, 不仅可以在paxos group 中进行搬迁direcotry, 也可以将一个paxos group 中的directory 添加或删除到一个新的paxos group.
- movedir 并不是一个事务, 为了不阻塞后续的读写.
- 它是后台进行数据搬迁, 如果大部分数据已经搬迁完, 剩下的数据通过事务来完成搬迁和元数据变更.
- placement 可以应用来确定
- placement language 单独负责副本配置管理.
- 管理控制2个维度
- 副本类型和数量
- 副本的地理placement
- 应用可以自由控制, 比如a的数据在欧洲有3个副本, b的数据在北美有5个副本.
数据模式
- 应用数据模型基于key-value的directory-bucket的分层模型. 一个应用在一个universe中创建一个或多个database. 每个database 可以包含无数个schemaed table. table 类似关系数据库的table, 有row, column和带版本的值.
- 数据模型并不是纯粹的关系模型, row 必须有名字. 每个表必须有一个或多个排好序的主键.
- 只要为某些key 定义了value(即使是null), 这些行都会存在. 选择key的区间, 可以决定数据放在哪些directory, 从而也就决定locality.
![Spanner: Google’s Globally Distributed Database]()
- example 显示:
- 通过interleave in 声明在schema 来定义table的hierachies.
- 一个hierachies的最顶部为directory table.
- 在directory table的每一行都有key, 它的后续关联table 和这个key 相关的所有行页放在这里, 按照字典序进行排列, 形成一个directory.
- on delete cascade 意味着 删除directory table的这一行, 会删除所有相关的child row.
- 这种方式, 保留了多个table 的相关性, 并具备相同的locality. 也会有更好的性能.

TrueTime
 1. 上图展示了truetime的api, truetime 用TTinterval来表示时间, 是一个不确定的时间间隔.
2. TTinterval 的端点是TTstamp.
3. TT.now 表示调用的绝对时间. time epoch 类似 unix的time(支持闰秒).
4. 定义瞬间error bound为ε, 是间隔的一半宽度
5. 平均error bound 为ε(带上划线)
6. 一个event的绝对时间用Tabs(e), tt = TT.now(), tt.earlist <= 0 1 4 6 7 30 200 tabs(enow) <="tt.latest." enow 是调用event 7. 使用gps 和原子钟作为truetime的参考, 因为他们有不同的失败模型. gps参考源的脆弱性包括天线和接收器故障,本地无线电干扰,相关故障(例如,设计错误,如不正确的闰秒处理和欺骗),以及gps系统停机。原子钟可能以与gps和彼此无关的方式失败,并且由于频率错误,长时间可能会产生显著的漂移。 8. 每个datacenter 有个time master, 每台机器上有个timeslave 后台进程. 大多数主服务器都有专用天线的gps接收器;这些主服务器都被物理分隔开以减少天线故障、无线电干扰和欺骗的影响。剩余的主服务器(我们称之为armageddon master)都配备了原子钟。一个原子钟并不那么昂贵:armageddon master的成本与gps主服务器的成本大致相当。所有主服务器的时间参考都定期互相对比。每个主服务器也会交叉检查其参考时间推进的速率与自己的本地时钟,并在存在大的偏差时剔除自己。在同步之间,armageddon master会宣布一个慢慢增加的时间不确定性,这是从保守应用的最坏情况时钟漂移中得出的。gps主服务器宣布的不确定性通常接近于零。 9. 每个守护进程都会查询各种主服务器,以减少对任何一个主服务器错误的敏感性。其中一些是从附近的数据中心选择的gps主服务器;其余的是来自较远数据中心的gps主服务器,以及一些 armageddon masters。守护进程应用marzullo的算法的一个变体来检测和拒绝说谎者,并将本地机器的时钟与非说谎者同步。为了防止本地时钟出错,那些表现出频率偏差大于由组件规格和操作环境派生出的最坏情况界限的机器将被逐出。正确性取决于确保最坏情况界限得到执行。 10. 在同步之间,守护进程会产生一个缓慢增加的时间不确定性。ε 是由保守地应用最坏情况的本地时钟漂移派生出来的。ε 还取决于timemaster的不确定性和与timemaster的通信延迟。在我们的生产环境中,ε 通常是时间的锯齿函数,每个轮询间隔从大约 到 毫秒变化。因此,ε 大部分时间都是 毫秒。守护进程的轮询间隔目前是 秒,当前应用的漂移率设置为每秒 微秒,这两者共同构成了从 毫秒的锯齿边界。剩下的 毫秒来自与时间主的通信延迟。在故障存在的情况下可能会偏离这个锯齿。例如,偶然的时间主不可用可能会导致数据中心范围内的 ε 增加。同样,过载的机器和网络连接可能会导致偶然的本地化 峰值。由于 spanner 可以等待不确定性,所以 的变化不会影响正确性,但是如果 增加太多,性能可能会降低。
1. 上图展示了truetime的api, truetime 用TTinterval来表示时间, 是一个不确定的时间间隔.
2. TTinterval 的端点是TTstamp.
3. TT.now 表示调用的绝对时间. time epoch 类似 unix的time(支持闰秒).
4. 定义瞬间error bound为ε, 是间隔的一半宽度
5. 平均error bound 为ε(带上划线)
6. 一个event的绝对时间用Tabs(e), tt = TT.now(), tt.earlist <= 0 1 4 6 7 30 200 tabs(enow) <="tt.latest." enow 是调用event 7. 使用gps 和原子钟作为truetime的参考, 因为他们有不同的失败模型. gps参考源的脆弱性包括天线和接收器故障,本地无线电干扰,相关故障(例如,设计错误,如不正确的闰秒处理和欺骗),以及gps系统停机。原子钟可能以与gps和彼此无关的方式失败,并且由于频率错误,长时间可能会产生显著的漂移。 8. 每个datacenter 有个time master, 每台机器上有个timeslave 后台进程. 大多数主服务器都有专用天线的gps接收器;这些主服务器都被物理分隔开以减少天线故障、无线电干扰和欺骗的影响。剩余的主服务器(我们称之为armageddon master)都配备了原子钟。一个原子钟并不那么昂贵:armageddon master的成本与gps主服务器的成本大致相当。所有主服务器的时间参考都定期互相对比。每个主服务器也会交叉检查其参考时间推进的速率与自己的本地时钟,并在存在大的偏差时剔除自己。在同步之间,armageddon master会宣布一个慢慢增加的时间不确定性,这是从保守应用的最坏情况时钟漂移中得出的。gps主服务器宣布的不确定性通常接近于零。 9. 每个守护进程都会查询各种主服务器,以减少对任何一个主服务器错误的敏感性。其中一些是从附近的数据中心选择的gps主服务器;其余的是来自较远数据中心的gps主服务器,以及一些 armageddon masters。守护进程应用marzullo的算法的一个变体来检测和拒绝说谎者,并将本地机器的时钟与非说谎者同步。为了防止本地时钟出错,那些表现出频率偏差大于由组件规格和操作环境派生出的最坏情况界限的机器将被逐出。正确性取决于确保最坏情况界限得到执行。 10. 在同步之间,守护进程会产生一个缓慢增加的时间不确定性。ε 是由保守地应用最坏情况的本地时钟漂移派生出来的。ε 还取决于timemaster的不确定性和与timemaster的通信延迟。在我们的生产环境中,ε 通常是时间的锯齿函数,每个轮询间隔从大约 到 毫秒变化。因此,ε 大部分时间都是 毫秒。守护进程的轮询间隔目前是 秒,当前应用的漂移率设置为每秒 微秒,这两者共同构成了从 毫秒的锯齿边界。剩下的 毫秒来自与时间主的通信延迟。在故障存在的情况下可能会偏离这个锯齿。例如,偶然的时间主不可用可能会导致数据中心范围内的 ε 增加。同样,过载的机器和网络连接可能会导致偶然的本地化 峰值。由于 spanner 可以等待不确定性,所以 的变化不会影响正确性,但是如果 增加太多,性能可能会降低。 并行控制
- 如何实现外部一致性事务, lock free 快照事务和过去的非阻塞读
![Spanner: Google’s Globally Distributed Database]()
- 单独的写转为读写事务, 无快照单独读转为快照读, 都是内部重试, 无需客户端做重试.
- 快照事务可以享受快照隔离性的优点.
- 快照事务必须声明无写操作. 并不是一个简单的不带写操作的读写事务.
- 快照读用一个获取的系统时间来执行, 并没有locking, 所以后续的写都是无锁的.
- 快照事务读中, 当任何一个副本都是update-to-date时, 都可以提供读服务
- 快照读事务中, 客户端可以选择一个timestamp 或者提供期望timestamp 区间的上限,从而spanner来选择一个时间.
- 在快照事务或快照读事务中, 一旦选择了timestamp, 就commit, 除非那个timestamp的数据被gc. 客户端可以避免不停retry.
- 当一个server失败时, 客户端会用timestamp和当前读位置, 从别的server 上进行读.
- paxos leader lease
- leader lease 大概10s. 当候选leader 获取多数派后, 它获得leader lease.
- 当leader lease 快超时, 当前leader 发起投票, 副本会在一个成功的写响应中携带lease 投票.
- 每个paxos group 的leader 都是不相交的.
- leader 可以通过lease 投票, 退位给slave.
- 读写事务都是严格的2阶段锁.
- 当获得所有的锁后并且还没有释放任何锁前, 他们会被分配timestamp, 这个timestamp 就是代表事务提交的paxos write的timestamp.
- 单调性
- paxos write 保持单调递增, 即使交叉leader. 通过利用leader的不交叉性, 强化了跨leader时的单调递增性.
- 一个leader 只能assign 它任期内的timestamp
- 任何时候, assign 一个timestamp, Smax 进阶到s 来保障不相交.
- 强化外部一致性
- T2 事务的起始时间在T1 事务的commit 时间之后, T2的commit 时间必须大于 T1的commit时间.
- 一个事务Ti的star 事件和commit 事件用E-i-star, E-i-commit(数学表达式, 不好用markdown来写, 转义一下), Ti 的commit timestamp 用Si 表示.
- 写事务Ti在协调者leader的cmmit 到达时间为E-i-server.
- Ti 事务的commit timestamp Si 不小于 TT.now().latest. 参与的leader 无关紧要.
- commit wait. 协调者保证客户端无法看到Ti commit的数据直到TT.after(si) 为true. commit wait 保障si 小于Ti的绝对commit 时间.
![Spanner: Google’s Globally Distributed Database]()
- 每个副本的同步时间称为safe time, Tsafe = min(T-safe-paxos, T-safe-TM),
- 每个paxos state 有一个safe time T-safe-paxos, 每个事务manager 有个T-safe-TM
- T-safe-paxos 简单, 是最高aplly的paxos write 时间. paxos的write 是单调递增并排序的.
- T-safe-TM 比较复杂
- 当没有prepared 事务时, 是无穷大. 也就是事务处在2阶段提交期间.
- 2阶段提交中, 每个参与者知道prepared 事务的timestamp的下限.
- 用S-i/g-prepare表示prepare record的prepare timestamp, 并保证事务的提交时间si >= S-i/g-prepare.
- T-safe-TM = min(all事务)(S-i/g-prepare) -1 时间.
- 快照事务执行2阶段提交,
- 分配一个timestamp S-read, 然后用S-read来读
- 最简单的方式: 当一个事务开启时, S-read = TT.now().latest. 但有的时候会遇到一些问题.
- 当副本的T-safe 还不足够时, 会block 在S-read上.
- 未来减少blocking, spanner 选择了保持外部一致性的最大时间.
- 读写事务
- 读写事务中的读使用wound-wait 方式来避免读写锁.
- 请求发到leader, 申请读锁和读取最新的数据
- 如果客户端事务重新打开, 使用keepalive 方式, 避免参与leader超时.
- 客户端选择协调者paxos group, 然后发送commit 信息带上协调者id和buffered 的写操作 到所有的参与leader.
- 当非协调者的leader 第一次申请写锁, 它会选择一个prepare timestamp, 这个timestamp 会比之前事务的timestamp 都要大, 并通过paxos 来写preprare record 的日志. 并通知协调者leader它的prepare timestamp.
- 当协调者第一次申请写锁时, 它会跳过prepare 阶段. 在收到所有参与者leader后, 它会选择一个timestamp 作为整个事务的timestamp(应该时commit timestamp).
- commit timestamp s 会比所有prepare timestamp 都要大或者和最大相等. 实际上会比协调者收到commit message 时的TT.now().latest 还要大.也会比之前所有的事务的所有timestamp 都要大.
- 然后协调者通过paxo log这个commit record.
- 只能paxo leader 才能申请锁. 仅仅当事务prepare 阶段才会log 锁的状态
- 如果在prepare之前丢失锁(死锁, paxos leader 变更, timeout等因素), 参与者会放弃.
- spanner 保证自由当所有的锁都hold 时, 才会去log 一个prepare或commit record.
- 如果leader 发送变更, 新leader 会在接受新事务之前, 恢复所有已经prepare但还没有uncommit事务的锁状态,
- 在所有的协调者的副本应用commit record之前, 协调者的leader会wait 直到TT.after(s), 从而可以遵守commit-wait 规则. 因为要保证TT.now().latest确实已经成为过去. 通常这个等待值是2倍的平均bound ε. 这个等待可以和paxos 通信并行.
- 在commit-wait 之后, 每个协调者会把commit timestamp 发给客户端和所有的参与者leader.
- 每个参与者log 这个事务的输出通过paxos 协议. 然后应用这个timestamp, 最后释放锁.
- 快照事务.
- 在分配timestamp之前, 需要这个read 所有涉及的paxos group leader 进行协商.
- 然后spanner require 一个scope expression, 这个expression 会总结这个读事务的key, 然后触发独立查询.
- 如果这个scope 的values 只涉及一个paxos group, 客户端就直接发送这个快照事务到这个paxos leader.
- 这个leader 会分配一个S-read, 并执行这个read.
- 对于单节点读, spanner 会比TT.now().latest做的更好.
- 定义LastTS() 为最后一个已经提交的写事务的timestamp.
- 如果没有prepared 事务, 直接S-read = LastTS() 来满足外部一致性.
- 如果是多paxos group 来
- 复杂的做法: 所有的参与者的leader 需要一起协商S-read 基于每个LastTS()
- 简单的做法(当前做法):客户端不用一轮协商, 直接选择一个安全的S-read=TT.now().latest.
- Schema-Change 事务:
- truetime 支持原子schema 变更.
- 使用标准的事务是不可行的, 因为参与者数以百万计
- bigtable 支持在一个datacent 进行原子schema change, 但这个操作会block 所有的操作
- 当前schema change事务是一个标准事务的无锁变种.
- 第一步, 分配一个未来时间的timestamp, 在prepare 阶段. 减少对数千个server 的当前业务产生冲击.
- 明显依赖这个schema的读写请求,把注册 schema-change的timestamp t 同步起来
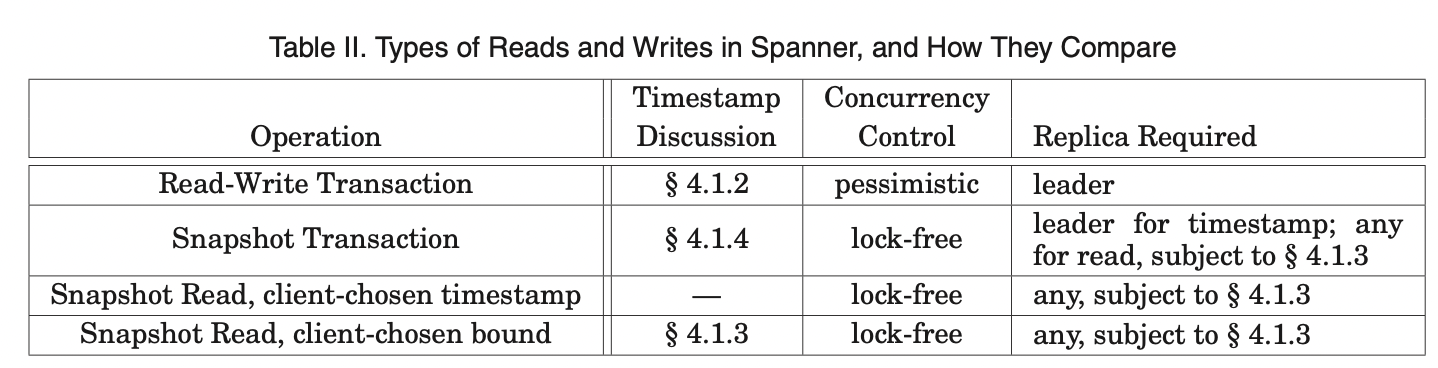
- 快照事务必须声明无写操作. 并不是一个简单的不带写操作的读写事务.
- 快照读用一个获取的系统时间来执行, 并没有locking, 所以后续的写都是无锁的.
- 快照事务读中, 当任何一个副本都是update-to-date时, 都可以提供读服务
- 当一个server失败时, 客户端会用timestamp和当前读位置, 从别的server 上进行读.
- leader lease 大概10s. 当候选leader 获取多数派后, 它获得leader lease.
- 当leader lease 快超时, 当前leader 发起投票, 副本会在一个成功的写响应中携带lease 投票.
- 每个paxos group 的leader 都是不相交的.
- leader 可以通过lease 投票, 退位给slave.
- 当获得所有的锁后并且还没有释放任何锁前, 他们会被分配timestamp, 这个timestamp 就是代表事务提交的paxos write的timestamp.
- 单调性
- paxos write 保持单调递增, 即使交叉leader. 通过利用leader的不交叉性, 强化了跨leader时的单调递增性.
- 一个leader 只能assign 它任期内的timestamp
- 任何时候, assign 一个timestamp, Smax 进阶到s 来保障不相交.
- T2 事务的起始时间在T1 事务的commit 时间之后, T2的commit 时间必须大于 T1的commit时间.
- 一个事务Ti的star 事件和commit 事件用E-i-star, E-i-commit(数学表达式, 不好用markdown来写, 转义一下), Ti 的commit timestamp 用Si 表示.
- 写事务Ti在协调者leader的cmmit 到达时间为E-i-server.
- Ti 事务的commit timestamp Si 不小于 TT.now().latest. 参与的leader 无关紧要.
- commit wait. 协调者保证客户端无法看到Ti commit的数据直到TT.after(si) 为true. commit wait 保障si 小于Ti的绝对commit 时间.
![Spanner: Google’s Globally Distributed Database]()
- 每个副本的同步时间称为safe time, Tsafe = min(T-safe-paxos, T-safe-TM),
- 每个paxos state 有一个safe time T-safe-paxos, 每个事务manager 有个T-safe-TM
- T-safe-paxos 简单, 是最高aplly的paxos write 时间. paxos的write 是单调递增并排序的.
- T-safe-TM 比较复杂
- 当没有prepared 事务时, 是无穷大. 也就是事务处在2阶段提交期间.
- 2阶段提交中, 每个参与者知道prepared 事务的timestamp的下限.
- 用S-i/g-prepare表示prepare record的prepare timestamp, 并保证事务的提交时间si >= S-i/g-prepare.
- T-safe-TM = min(all事务)(S-i/g-prepare) -1 时间.

- 分配一个timestamp S-read, 然后用S-read来读
- 最简单的方式: 当一个事务开启时, S-read = TT.now().latest. 但有的时候会遇到一些问题.
- 当副本的T-safe 还不足够时, 会block 在S-read上.
- 未来减少blocking, spanner 选择了保持外部一致性的最大时间.
- 读写事务中的读使用wound-wait 方式来避免读写锁.
- 请求发到leader, 申请读锁和读取最新的数据
- 如果客户端事务重新打开, 使用keepalive 方式, 避免参与leader超时.
- 客户端选择协调者paxos group, 然后发送commit 信息带上协调者id和buffered 的写操作 到所有的参与leader.
- 当非协调者的leader 第一次申请写锁, 它会选择一个prepare timestamp, 这个timestamp 会比之前事务的timestamp 都要大, 并通过paxos 来写preprare record 的日志. 并通知协调者leader它的prepare timestamp.
- 当协调者第一次申请写锁时, 它会跳过prepare 阶段. 在收到所有参与者leader后, 它会选择一个timestamp 作为整个事务的timestamp(应该时commit timestamp).
- commit timestamp s 会比所有prepare timestamp 都要大或者和最大相等. 实际上会比协调者收到commit message 时的TT.now().latest 还要大.也会比之前所有的事务的所有timestamp 都要大.
- 然后协调者通过paxo log这个commit record.
- 只能paxo leader 才能申请锁. 仅仅当事务prepare 阶段才会log 锁的状态
- 如果在prepare之前丢失锁(死锁, paxos leader 变更, timeout等因素), 参与者会放弃.
- spanner 保证自由当所有的锁都hold 时, 才会去log 一个prepare或commit record.
- 如果leader 发送变更, 新leader 会在接受新事务之前, 恢复所有已经prepare但还没有uncommit事务的锁状态,
- 在所有的协调者的副本应用commit record之前, 协调者的leader会wait 直到TT.after(s), 从而可以遵守commit-wait 规则. 因为要保证TT.now().latest确实已经成为过去. 通常这个等待值是2倍的平均bound ε. 这个等待可以和paxos 通信并行.
- 在commit-wait 之后, 每个协调者会把commit timestamp 发给客户端和所有的参与者leader.
- 每个参与者log 这个事务的输出通过paxos 协议. 然后应用这个timestamp, 最后释放锁.
- 在分配timestamp之前, 需要这个read 所有涉及的paxos group leader 进行协商.
- 然后spanner require 一个scope expression, 这个expression 会总结这个读事务的key, 然后触发独立查询.
- 如果这个scope 的values 只涉及一个paxos group, 客户端就直接发送这个快照事务到这个paxos leader.
- 这个leader 会分配一个S-read, 并执行这个read.
- 对于单节点读, spanner 会比TT.now().latest做的更好.
- 定义LastTS() 为最后一个已经提交的写事务的timestamp.
- 如果没有prepared 事务, 直接S-read = LastTS() 来满足外部一致性.
- 如果是多paxos group 来
- 复杂的做法: 所有的参与者的leader 需要一起协商S-read 基于每个LastTS()
- 简单的做法(当前做法):客户端不用一轮协商, 直接选择一个安全的S-read=TT.now().latest.
- Schema-Change 事务:
- truetime 支持原子schema 变更.
- 使用标准的事务是不可行的, 因为参与者数以百万计
- bigtable 支持在一个datacent 进行原子schema change, 但这个操作会block 所有的操作
- 当前schema change事务是一个标准事务的无锁变种.
- 第一步, 分配一个未来时间的timestamp, 在prepare 阶段. 减少对数千个server 的当前业务产生冲击.
- 明显依赖这个schema的读写请求,把注册 schema-change的timestamp t 同步起来