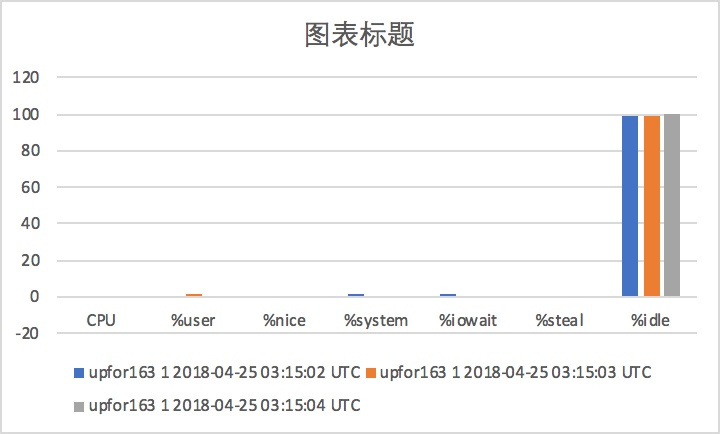
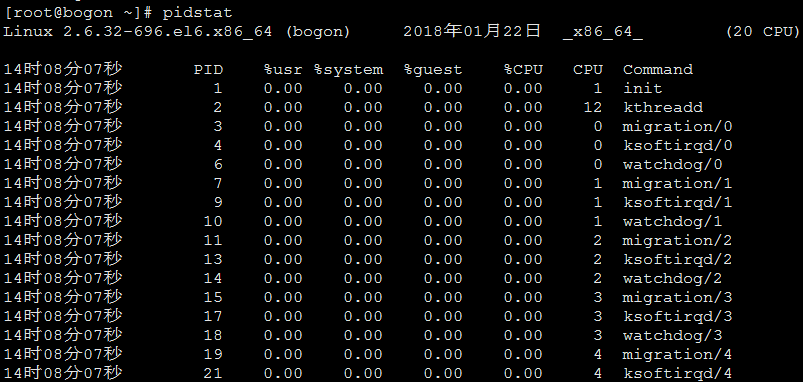
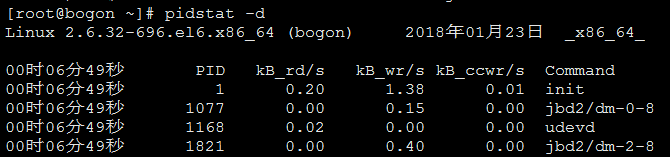
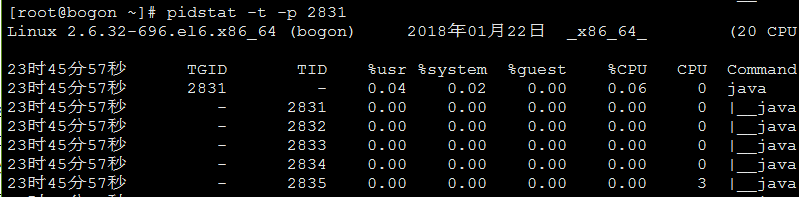
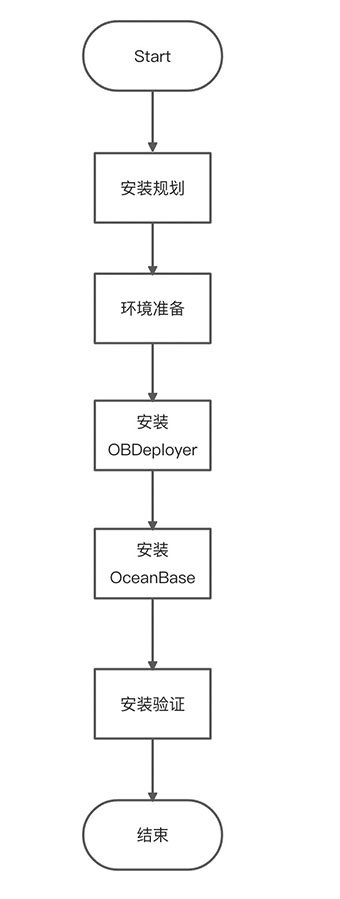
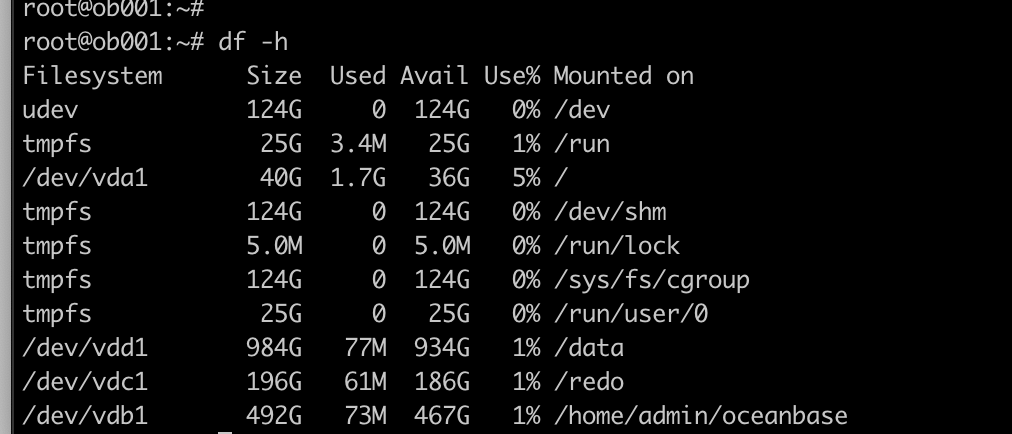
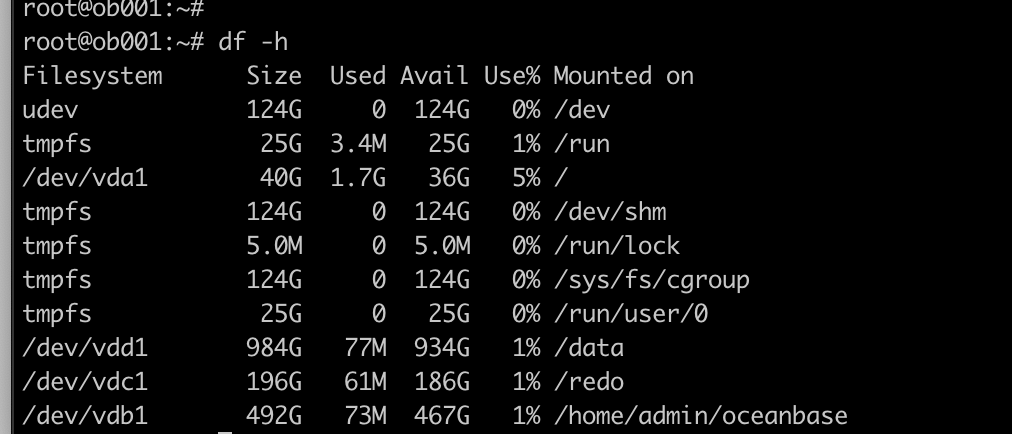
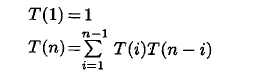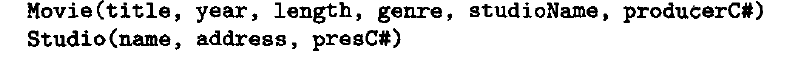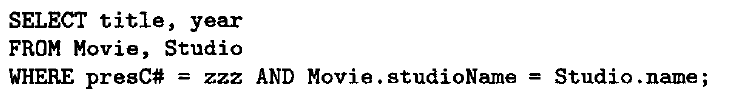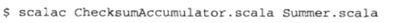随谈
万字 大文章 https://mp.weixin.qq.com/s/Y2A7-Ui2nzUgodkEbgR6lQ
有很多理念,还是比较认同的:
- 技术挑战 放到 开源里面做, 这一点不是很认同, 我认为, 开源解决的是规模小的需求, 或者某个特定的的非常common的问题, 而当规模上来后, 是需要商业化来解决, 或者当需求变得复杂, 需要一系列的措施来解决, 是需要商业化的技术方案来解决.
- 个人或者小的团队, 就应该免费使用, 这个逻辑基本成立. 跨团队协作的需求, 商业化机会比较大
- 要把价格门槛低的核心产品做的简单易用,同时又要兼顾未来组织内部对产品的复杂需求。 – 这个很认同
- 即使某些功能在开源中有,但是这些功能无法从一个完整的use case level来解决企业面对的问题。 真实操作中, 会将这个放大.
- 讨论放到一个具体的use case,而不是某一个功能,这样对于sales也会更好沟通
- 开源公司要拿到一些客户订单并不难。但是这里说到市场和销售,核心是repeatable/scalable。
- 利用开源形成事实标准,是企业最牢固的隐形护城河。
- 开源模式下,sales最大的挑战就是公司自己的开源产品。
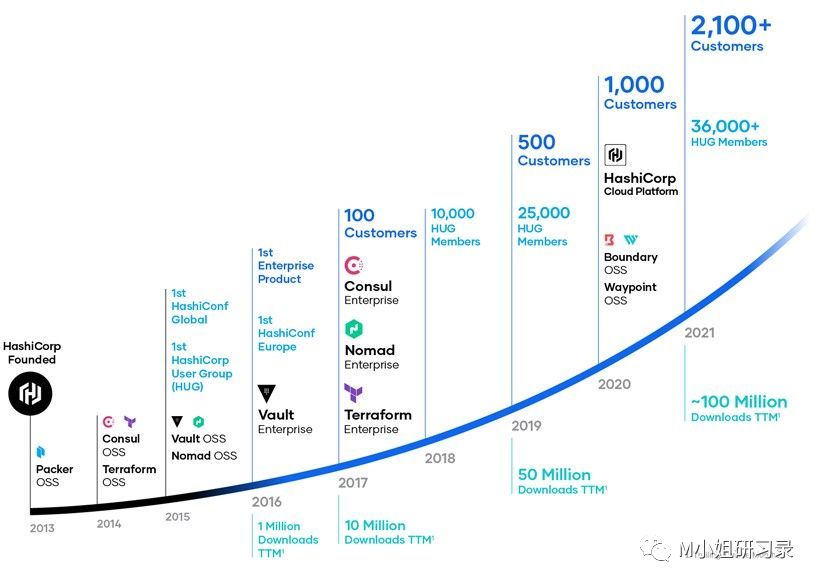
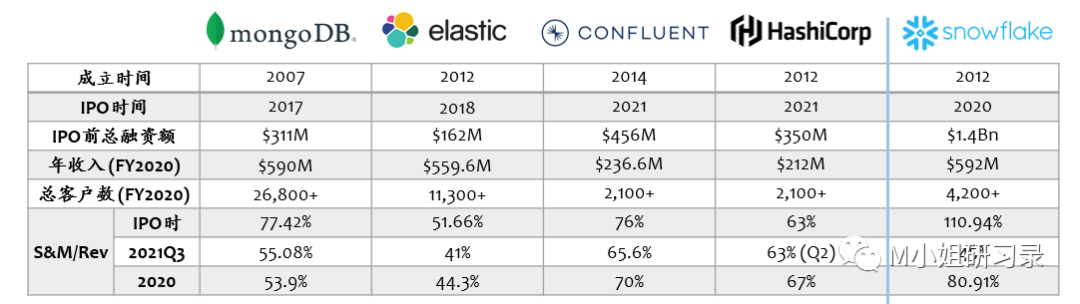
- 开源模式的S&M (Sales & Marketing)花费应该比传统软件公司要少呀。但是Hashicorp S&M/Rev 比例超过60%,在整个public SaaS公司中,算是比较高的了. 时代在变, 有很多开源运作的成本, 处于技术和品牌交叉的, 这块如果放在marketing, 自然markteing的成本会大幅上升, 而且这个会成为趋势.
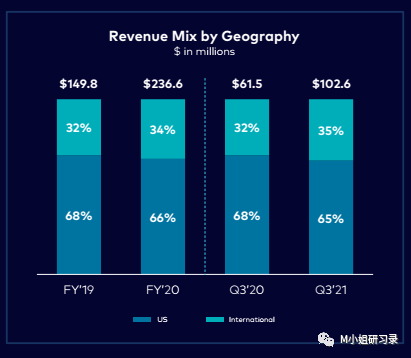
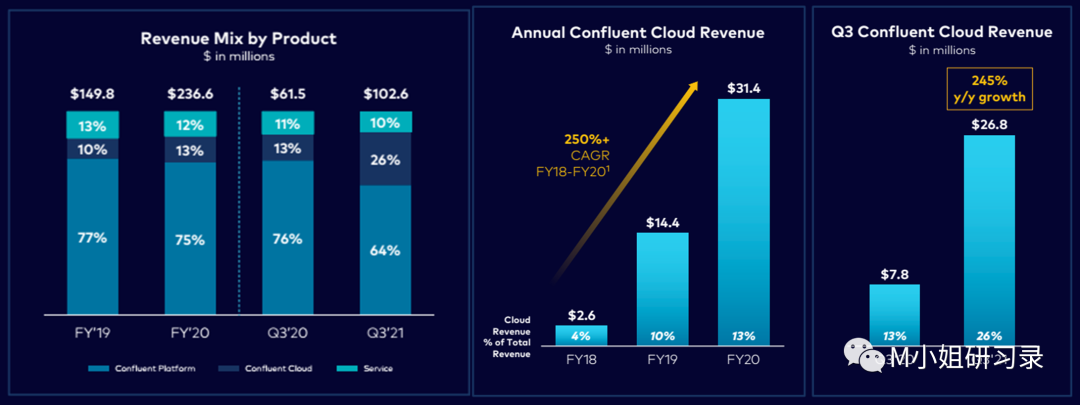
- 开源天生就是global的生意。– Hashicorp和Confluent的国际业务发展都很快。两家商业化都是5年左右的时间,都已经有35%的收入来自美国以外。
- 渠道玩得溜溜的 – Hashicorp在开始商业化以后第二年就开始大力发展partners, 三四年的时间,已经建立起来一个170+ ISVs,超过450个integration partner的网络
- 面对大客户,只是交给对方工具远远不够。 – 最先进的enterprise software公司,输出的不仅是工具,更是工具背后的方法论(当然,输出方法论的成本也是不低的)。 – 于这样一个大工程,你不能光是提供一系列工具,还要向他们展示the way to get there. – 工具类产品比拼的往往不是单纯的性能,而是工具背后的代表新的生产方式的方法论。把best practice抽象成方法论,难度可不比工程上的性能提升要小。一旦让这个方法论成为事实标准,才是真正的护城河。
- 护城河绝不是单纯把产品做成大而全的平台,把一堆60-70分的产品盲目堆砌起来。
- Hashicorp的S-1中,把这个模式进一步细化为adopt, land, expand, and extend。其实本质也是PLG里的套路:
- 用社区/marketing促进Adopt
- 用简单易上手的产品+初始低价降低初始Landing的门槛
- 基于Usage实现自然增长Expand
- 最后用product portfolio在每个cohort中Extend
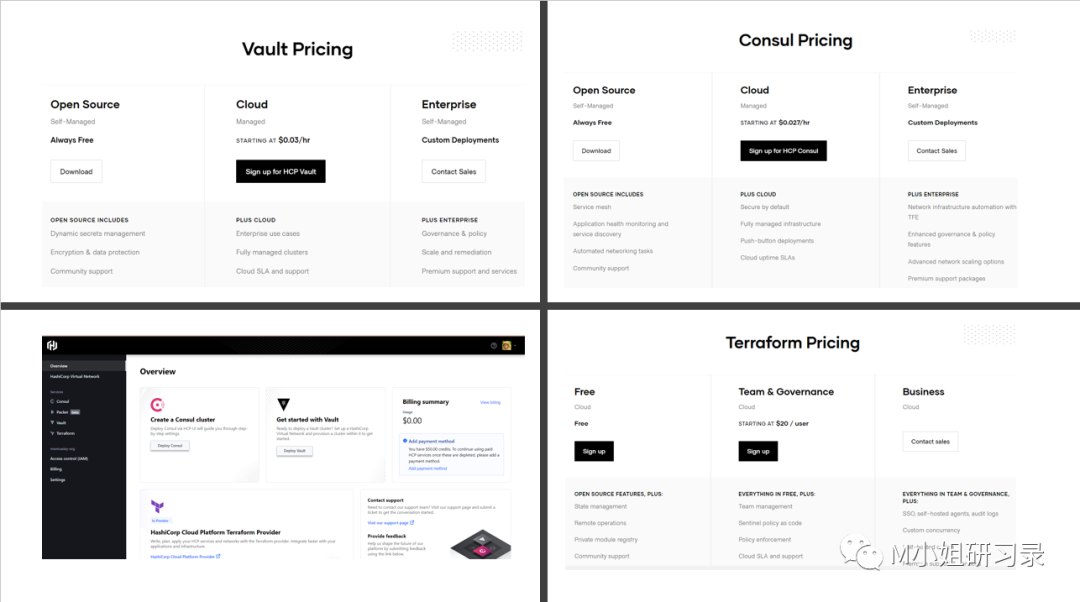
- 在SaaS land&expand这个模式中,不可缺少的一环就是usage-based pricing。– 看看现在HCP上几个产品的pricing,你也许会发现一个问题,就是这个pricing unit的设计其实很有讲究。– 你设定的pricing unit除了要计算方便之外,必须避免Usage is discouraged when customers feel the marginal cost of consumption
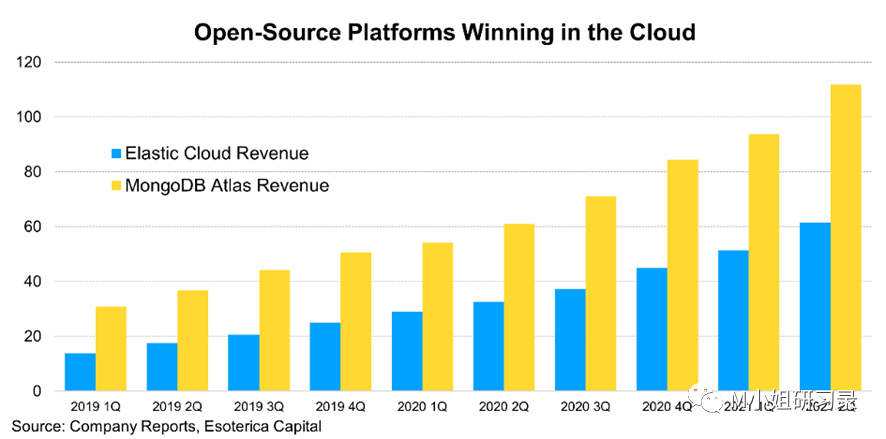
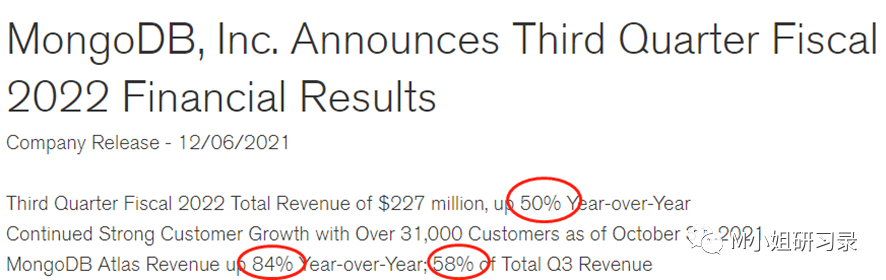
- etl 公司, Airbyte(https://github.com/airbytehq/airbyte), – 刚刚close了B轮融资$150M, 估值已经飙升到$1.5Bn!不到20个月,已经刷刷刷地三轮融了$181M
- 在SaaS模式已经被广泛接受的年代,后来者迅速开发Cloud版本抢占“基层”市场,几乎是个定式,只会到来得越来越快。
- Win developer’s mind and heart! hashcorp – 他们旗下的repo加起来超过220k stars
- 几乎没有哪个成功的开源社区,早期的时候没有在线下做大量后来看起来完全不scalable的事情。 纯粹误解: Github一上线,HN、Reddit各种线上宣传一下,回答问题和PR,然后做好技术和performance,社区啊用户啊就应该自己围过来了么?
- 首先,Meetup不可少,抓住各种community抱大腿。– 一开始靠身边的亲朋好友宣传,速度当然很慢。后来,两位创始人很积极到各种Seattle当地的社区meetup、Ruby社区、QCon,DevOpsDay等等,在各种活动上寻找刷脸的机会
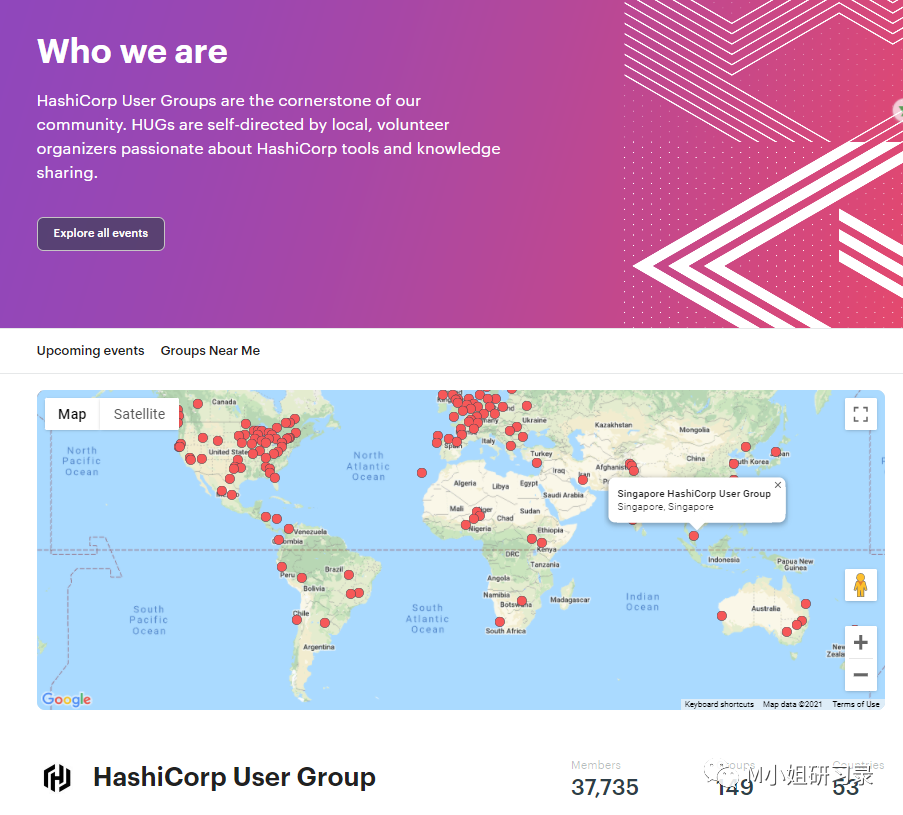
- Hashicorp就开始全方位建立自己的社区,其中最重要的就是HUG - Hashicorp User Groups. 这个分散在世界各地的自发性组织,如今已经有37k+的会员,遍及53个国家。各种自发的Meetup和活动,不断深化与开发者的关系
- Hashicorp对于Conference的投入格外重视。
- 特别重要的是,主动出击,在一线跟早期用户深度交流。
- 你要能叫出你的项目前100个用户的名字!
- 社区不是最终目的。M小姐认为,终极目标,还是成为行业的事实标准. – 要实现这一点,产品设计、社区搭建,以及商业伙伴的合作,是不可割裂的整体。
- 从产品设计上来说:不要憋大招,第一个产品只要能prove idea就可以。
- 简单对比了几个比较顶尖的开源项目Star数和Contributor的比例,很有意思的发现是,这个比例惊人的相似,几乎都在0.03!
- 有些开源公司将社群运营看成了一个纯粹marketing的“用户社区”,忽视了开源这个复杂生态中,每个stakeholder的重要性。– 要能在商业有起色之前,有如此热血的坚持,真爱是必要条件。
- 产品设计的一套方法论, 首先,永远被摆在第一位的,Built for workflow, not technologies. – 他们将workflow拆解成三个部分:People, process, tools. – 设计一个workflow产品/工具的时候,很多人只是看着工具本身的功能,而没有想到,这里面对人的技能的要求是怎样的,对IT流程的假设是self-service还是工单系统,这些随着环境和具体技术的变化,有什么可以抽象出来保持一致的?
- 尊重技术,但是更要重视human element. 就像前面说的Cloud Operation Model.他们发现你不能直接把最终的牛逼哄哄的最佳实践给客户,向客户展现your way to get there,就要接受在这个过程中一些不那么完美的方案。
- 跟很多开源公司很像,Hashicorp也遵循transparent operation的理念,将公司的很多管理细则、决策原则等等,都公开在网上. 这个挺难的, 刚开始还比较容易, 当商业化逐渐深入, 很多事情反而扑朔迷离.
- 两家公司都非常非常强调writing以及Over communication! 这个不错.



 ]]>
]]>

































 最后一个景点, 芦苇海
最后一个景点, 芦苇海 ]]>
]]>







 一进门就是与众不同的柱子
一进门就是与众不同的柱子
























































 ]]>
]]>










 ### 第四程/第五程, 大巴和火车因为第四程和第五程,天色以黑, 也看不到什么东西, 在车上已经有点昏昏欲睡。 不过这一段路程,如果是在夏天,就可以看到火车沿着海岸线行走,看沿途的大海。]]>
### 第四程/第五程, 大巴和火车因为第四程和第五程,天色以黑, 也看不到什么东西, 在车上已经有点昏昏欲睡。 不过这一段路程,如果是在夏天,就可以看到火车沿着海岸线行走,看沿途的大海。]]>























 阿曼达雕像, 波罗的海女儿
阿曼达雕像, 波罗的海女儿 国家音乐厅门前
国家音乐厅门前 最火的网红餐厅前, 玻璃屋前的街景]]>
最火的网红餐厅前, 玻璃屋前的街景]]>


 放一张美女镇楼
放一张美女镇楼 在极光下, 向爱人示爱或求婚, 是不是非常浪漫呢?
在极光下, 向爱人示爱或求婚, 是不是非常浪漫呢?
 应广大群众要求,放2张楼主照片看一次极光,一位大人差不多要900一次,如果提前预定了,但当晚没有极光或者云比较多,也看不到,白白浪费钱, 因此,建议不要提前进行预定, 等到了罗瓦涅米, 在下午5点时,根据情况再决定是否要预定还是不预定。 1. 下2个app, "Aurora Map" 和 “Aurora Now” 2个app,2. 下了app 后,在app上看当地的kp (是叫电磁强度还是太阳风暴强度不记得了),里面会对当晚或后面几天kp进行预测, 如果当晚kp 不高(小于3),就建议不要预定了。 大于等于3 就可以考虑了3. 如果5点左右还在下雨或云层比较厉害, 在app再看看cloud 预测,如果cloud 很厉害,也不用看4. 如果kp和cloud 都满足条件, 赶紧上www.nordictravels.eu 这家网站, 下订单, 可以直接打电话给他们,他们提供中文电话服务。 5. 下单推荐下极光摄影团项目, 旅行社他们一个大巴40/50人,会配上2个摄影师,专门帮助大家拍照, 而且他们拍照经验相对而已还是非常丰富, 比大部分摄影菜鸟还是要强很多。 另外第二次报名时, 直接半价。
应广大群众要求,放2张楼主照片看一次极光,一位大人差不多要900一次,如果提前预定了,但当晚没有极光或者云比较多,也看不到,白白浪费钱, 因此,建议不要提前进行预定, 等到了罗瓦涅米, 在下午5点时,根据情况再决定是否要预定还是不预定。 1. 下2个app, "Aurora Map" 和 “Aurora Now” 2个app,2. 下了app 后,在app上看当地的kp (是叫电磁强度还是太阳风暴强度不记得了),里面会对当晚或后面几天kp进行预测, 如果当晚kp 不高(小于3),就建议不要预定了。 大于等于3 就可以考虑了3. 如果5点左右还在下雨或云层比较厉害, 在app再看看cloud 预测,如果cloud 很厉害,也不用看4. 如果kp和cloud 都满足条件, 赶紧上www.nordictravels.eu 这家网站, 下订单, 可以直接打电话给他们,他们提供中文电话服务。 5. 下单推荐下极光摄影团项目, 旅行社他们一个大巴40/50人,会配上2个摄影师,专门帮助大家拍照, 而且他们拍照经验相对而已还是非常丰富, 比大部分摄影菜鸟还是要强很多。 另外第二次报名时, 直接半价。  推荐玩法:1. 第一天在飞猪或nodict官网下单, 让他们的教练先教我们一下基本的动作, 另外, 也会带我们去滑雪场和租赁中心租设备。2. 如果后面想自己去滑雪, 就可以自己几个人组个团,租一辆车,带上中午吃的一些东西, 自己去昨天的滑雪场和租赁中心进行租赁。
推荐玩法:1. 第一天在飞猪或nodict官网下单, 让他们的教练先教我们一下基本的动作, 另外, 也会带我们去滑雪场和租赁中心租设备。2. 如果后面想自己去滑雪, 就可以自己几个人组个团,租一辆车,带上中午吃的一些东西, 自己去昨天的滑雪场和租赁中心进行租赁。  然后船航行差不多一个小时后, 到了一个稍微开阔的水域, 船停在这里,让大家穿着虾服, 可以下水游泳, 游完泳, 大家上船换羽绒服,然后到冰封的海面上玩, 堆堆雪人拍拍照, 冰封的海面,一望无际, 小朋友可以在这里打打雪仗,堆堆雪人,大人可以多拍拍照片。
然后船航行差不多一个小时后, 到了一个稍微开阔的水域, 船停在这里,让大家穿着虾服, 可以下水游泳, 游完泳, 大家上船换羽绒服,然后到冰封的海面上玩, 堆堆雪人拍拍照, 冰封的海面,一望无际, 小朋友可以在这里打打雪仗,堆堆雪人,大人可以多拍拍照片。  另外, 玩破冰船的,中午会在瑞典一个小镇上 吃午餐,这个小镇的风景非常漂亮,无论是冬天还是夏天,景色都是非常迷人, 可以驻足拍照一段时间。
另外, 玩破冰船的,中午会在瑞典一个小镇上 吃午餐,这个小镇的风景非常漂亮,无论是冬天还是夏天,景色都是非常迷人, 可以驻足拍照一段时间。 整体而已, 破冰船,玩一次就够了,下次估计就不会再想玩了。 一点小建议就是, 破冰船如果想玩,可以提前在双11 预定, 会有一点小红包。
整体而已, 破冰船,玩一次就够了,下次估计就不会再想玩了。 一点小建议就是, 破冰船如果想玩,可以提前在双11 预定, 会有一点小红包。 

 如果住圣诞老人村的话, 其实这个活动,不需要报这个项目, 因为, 基本上见圣诞老人, 哈士奇雪橇,驯鹿雪橇都是在圣诞老人村, 自己都可以自费玩, 而且费用上自己玩可能更便宜一点, 另外一点时间上会比较自由, 不过,还是推荐雪地摩托, 我看很多老外都有选择雪地摩托,还是对这个有点期待。
如果住圣诞老人村的话, 其实这个活动,不需要报这个项目, 因为, 基本上见圣诞老人, 哈士奇雪橇,驯鹿雪橇都是在圣诞老人村, 自己都可以自费玩, 而且费用上自己玩可能更便宜一点, 另外一点时间上会比较自由, 不过,还是推荐雪地摩托, 我看很多老外都有选择雪地摩托,还是对这个有点期待。 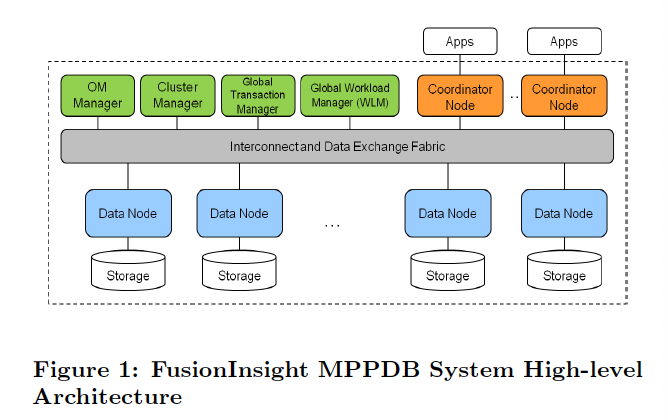
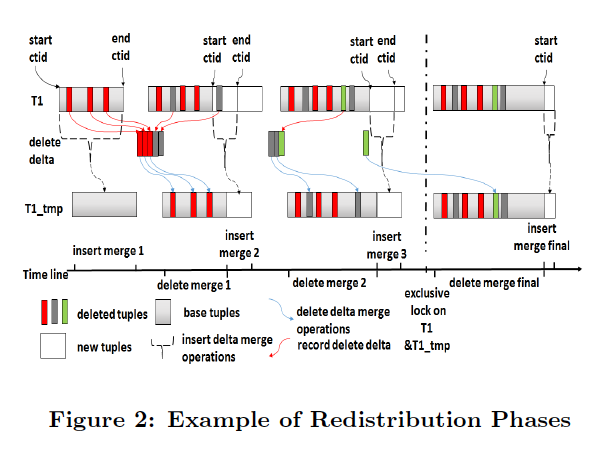
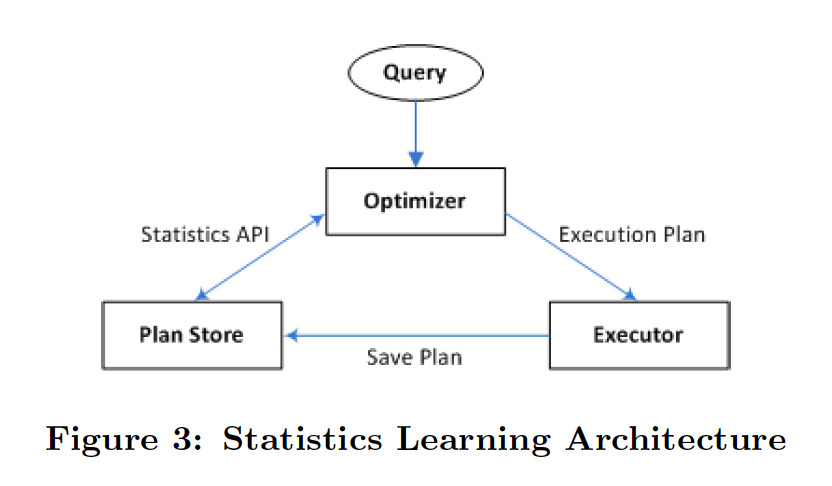
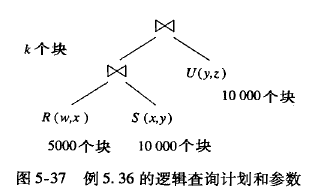
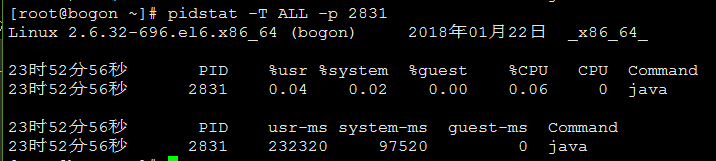
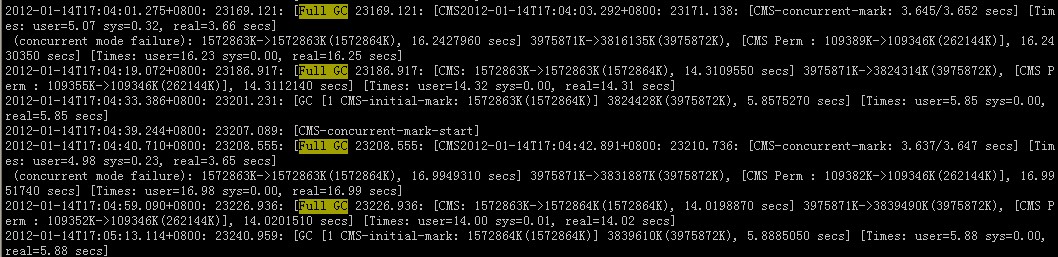
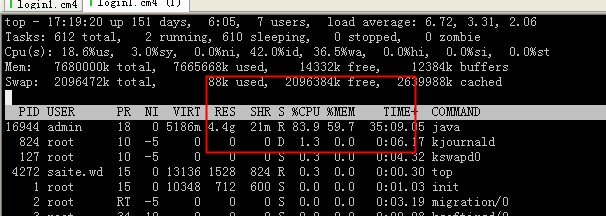
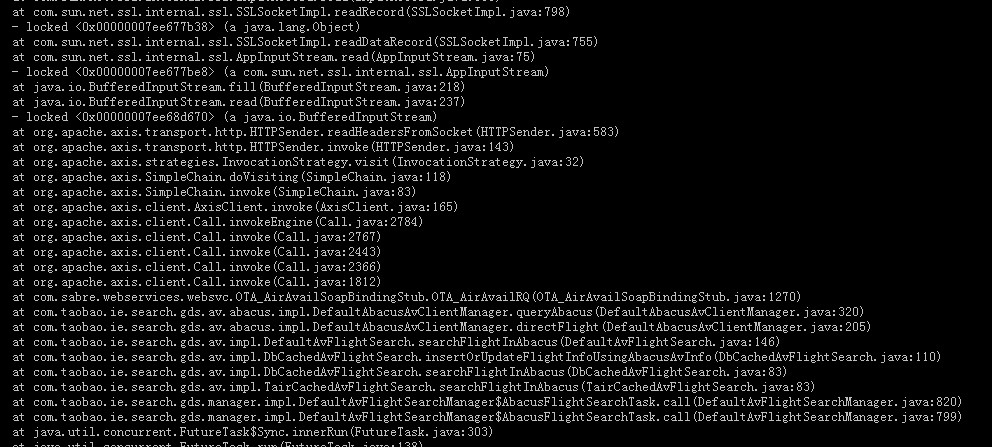
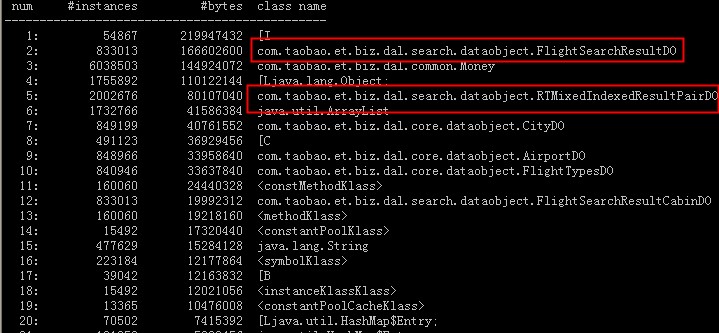
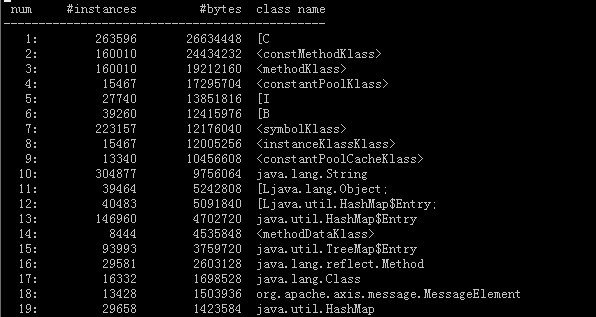
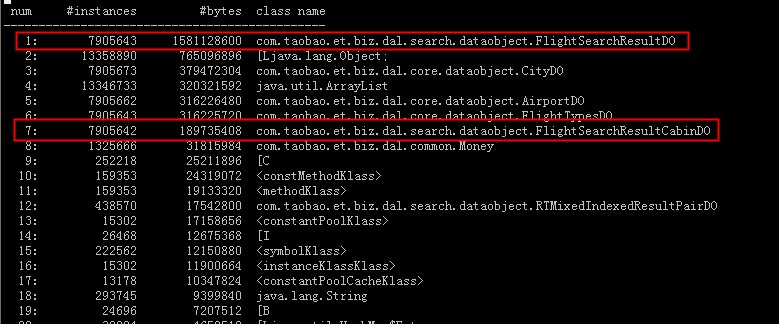
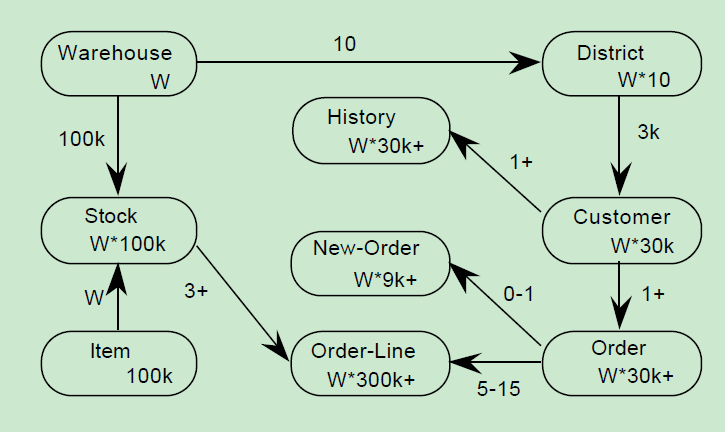
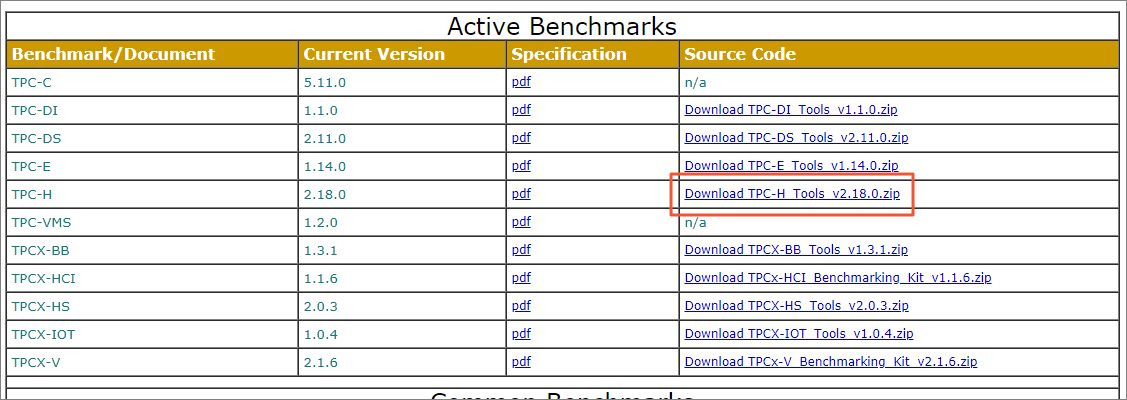
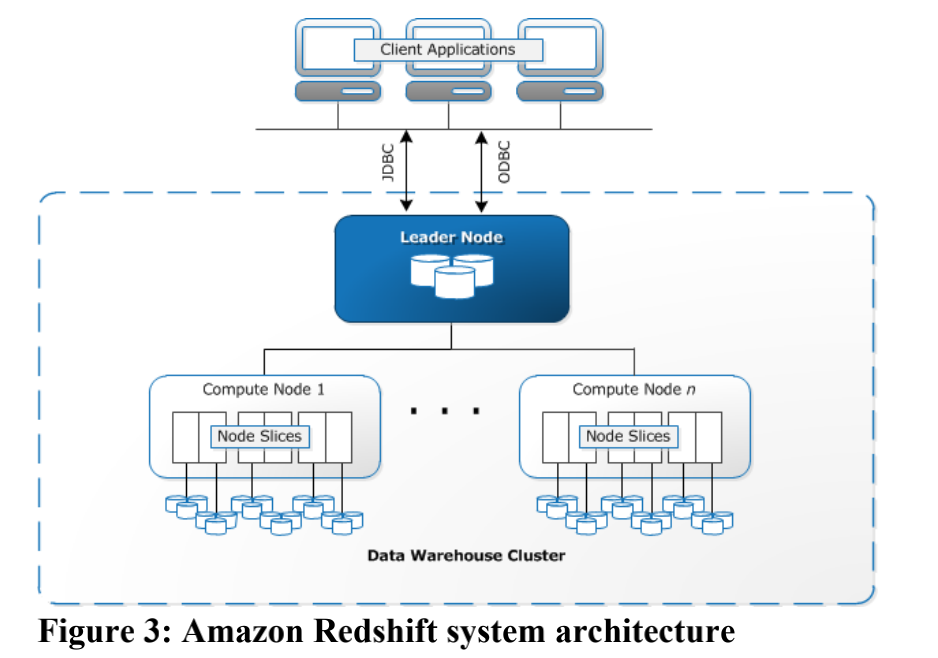
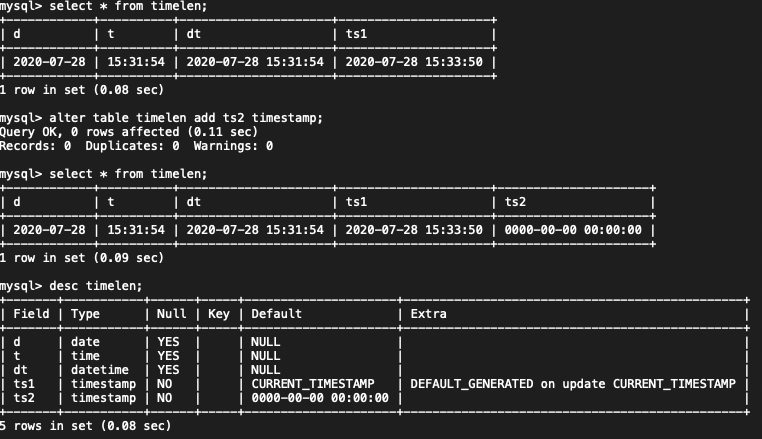
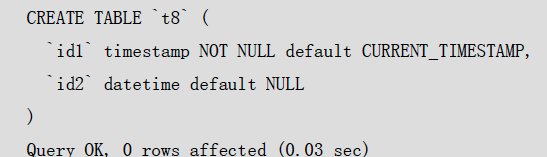
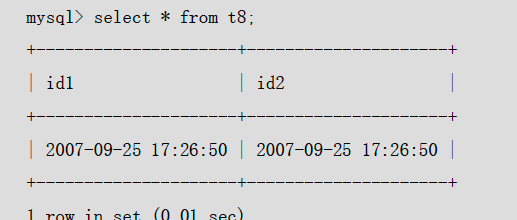
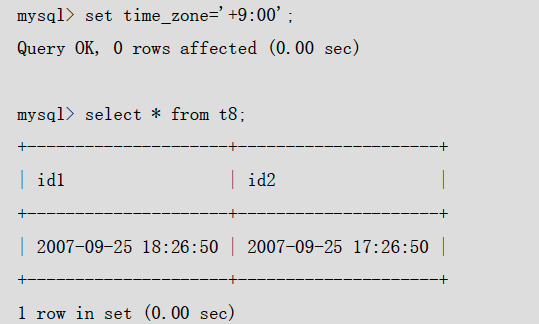
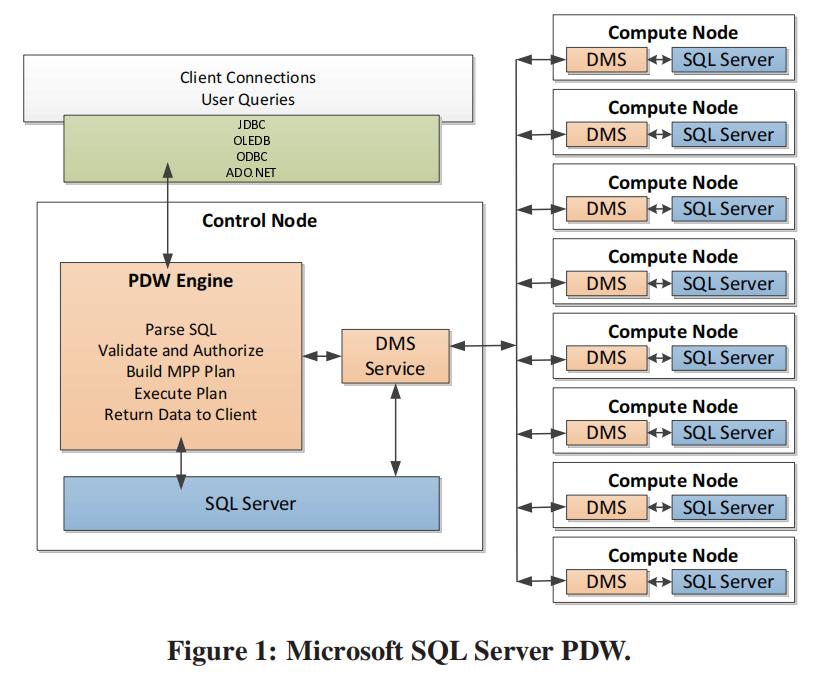
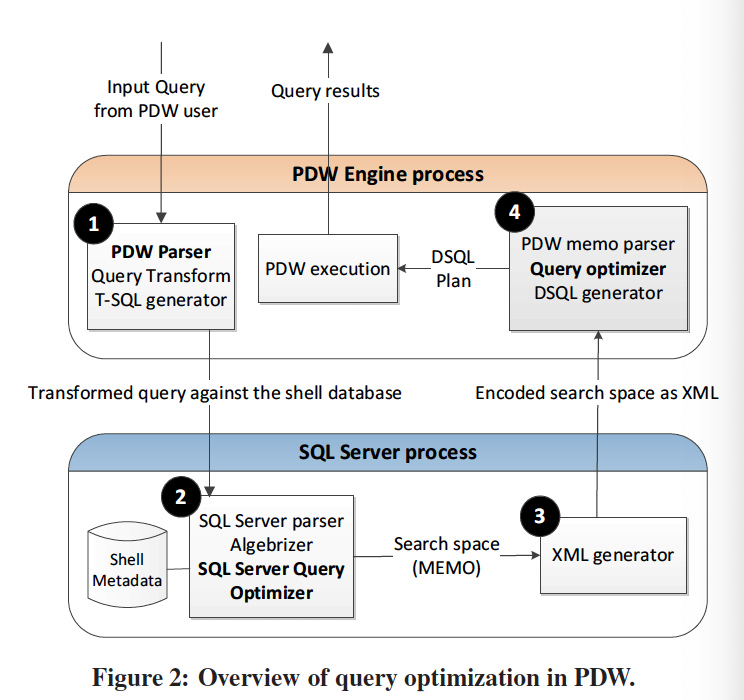
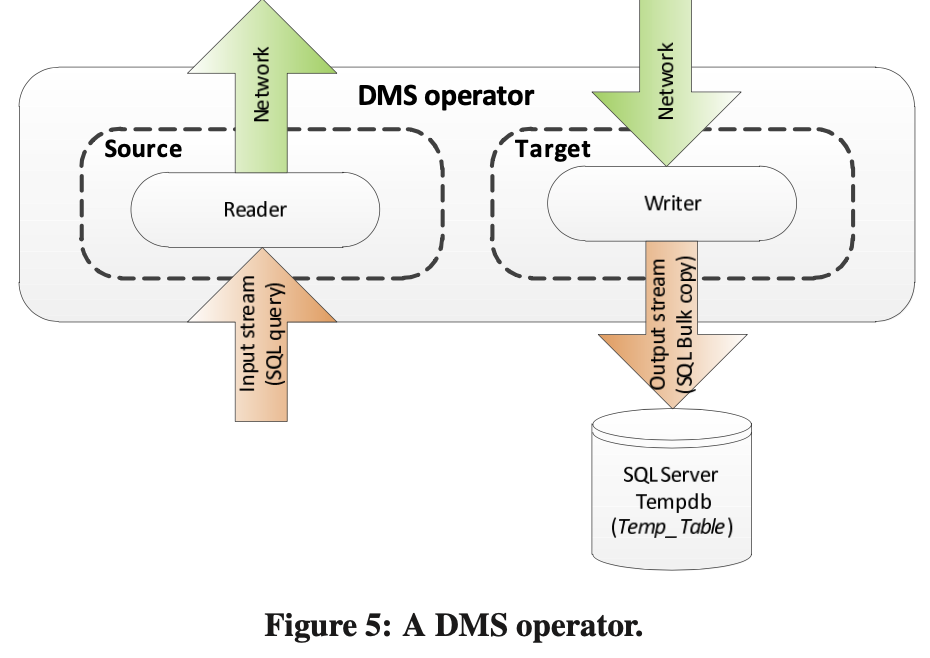
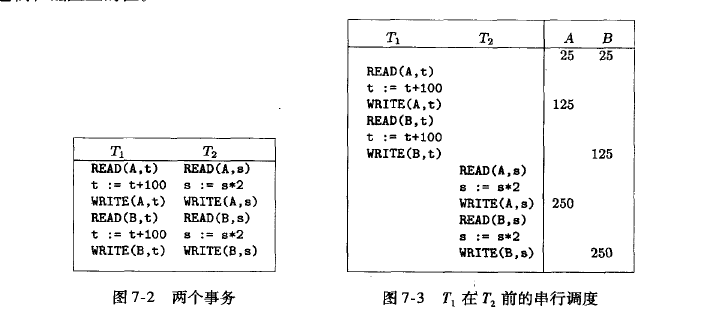
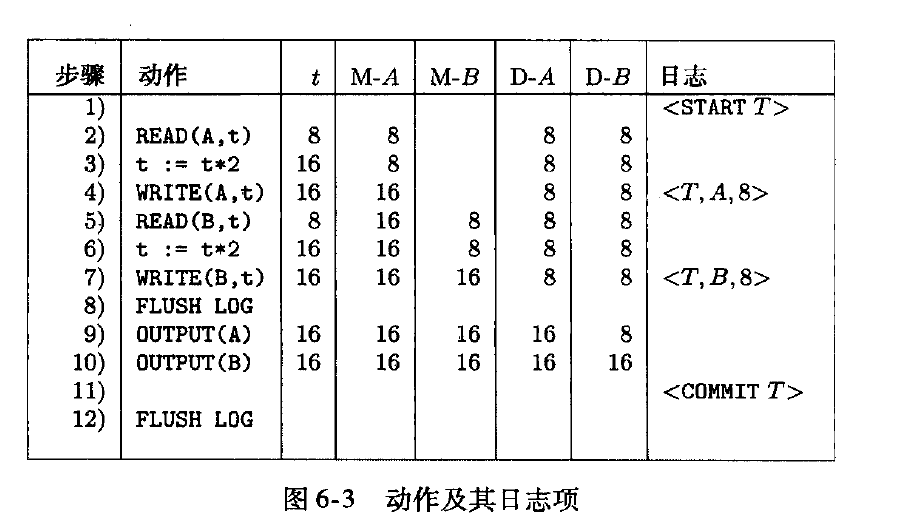
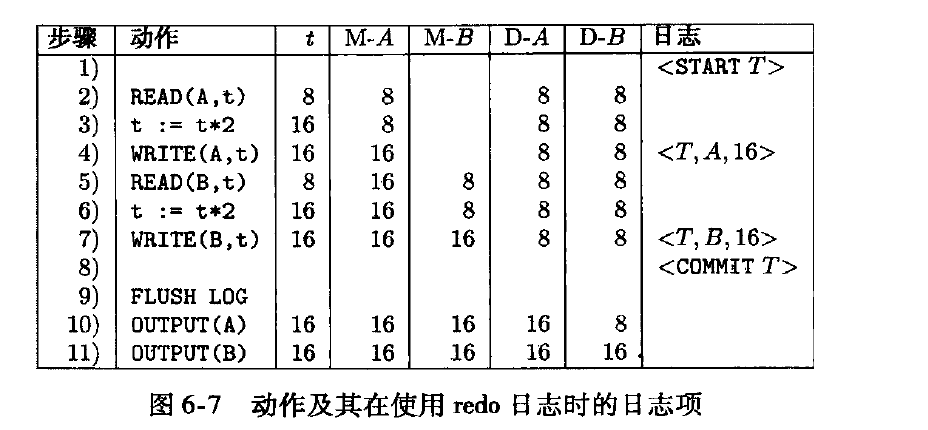
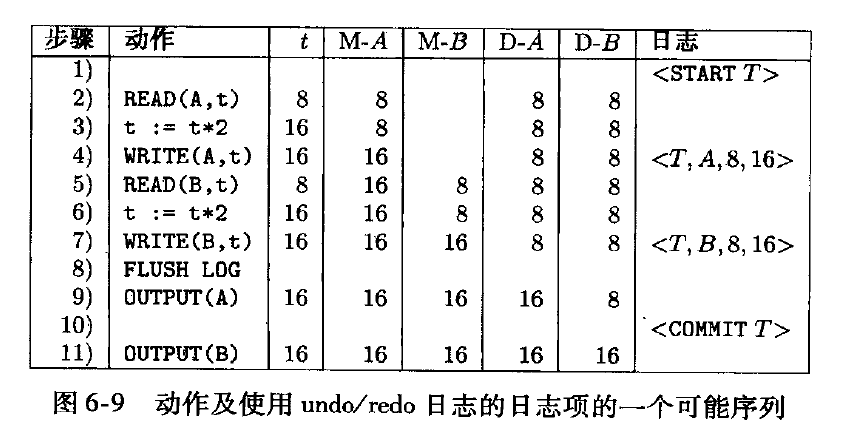
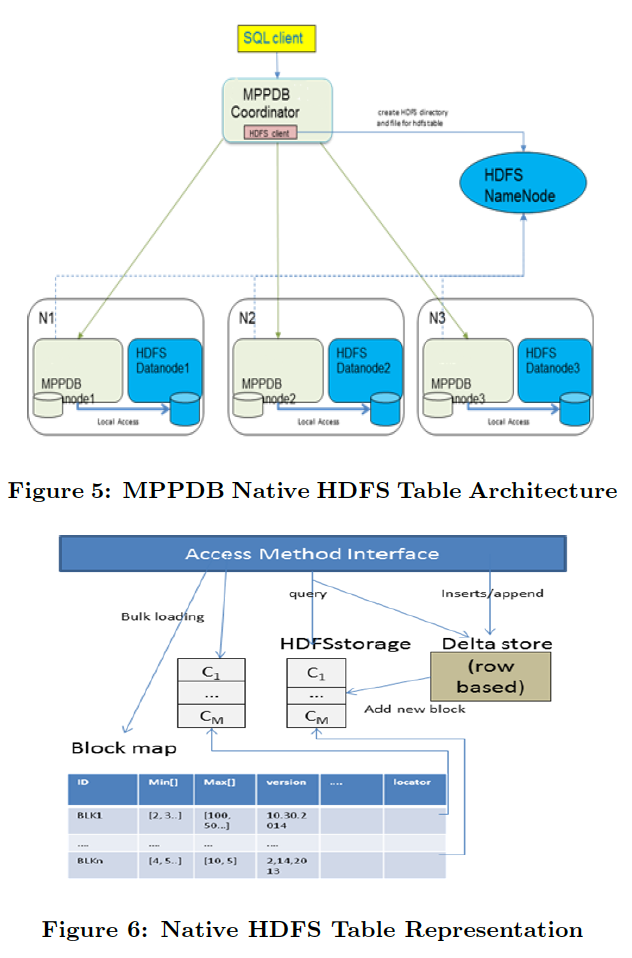 通过pq foreign data wrapper来访问hdfs, bypass hadoop mr 框架, 引入一个调度器, 动态吧文件的分片分配到mpp的节点上进行计算, 一个hdfs目录被影射到db的外表,这个外表支持分区表。 因为hdfs的分区是基于目录的, 优化器可用做一些优化操作从而跳过一些分区而减少io操作。 支持orc或parque 格式, 这些格式内部保护一些index,充分利用这些信息。 hdfs 客户常常有2个额外的要求, 1. dml和acid 支持; 2. 要求更好的性能(需要知道data collocation)
通过pq foreign data wrapper来访问hdfs, bypass hadoop mr 框架, 引入一个调度器, 动态吧文件的分片分配到mpp的节点上进行计算, 一个hdfs目录被影射到db的外表,这个外表支持分区表。 因为hdfs的分区是基于目录的, 优化器可用做一些优化操作从而跳过一些分区而减少io操作。 支持orc或parque 格式, 这些格式内部保护一些index,充分利用这些信息。 hdfs 客户常常有2个额外的要求, 1. dml和acid 支持; 2. 要求更好的性能(需要知道data collocation)
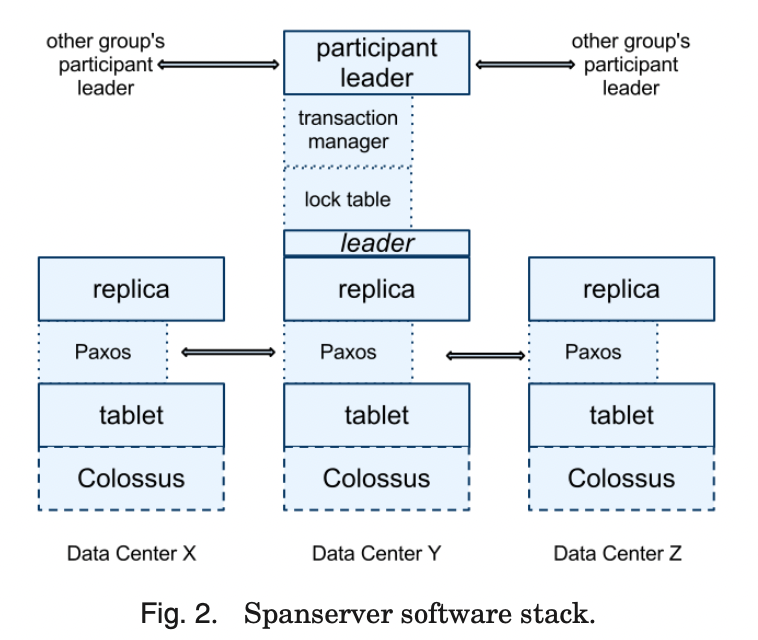

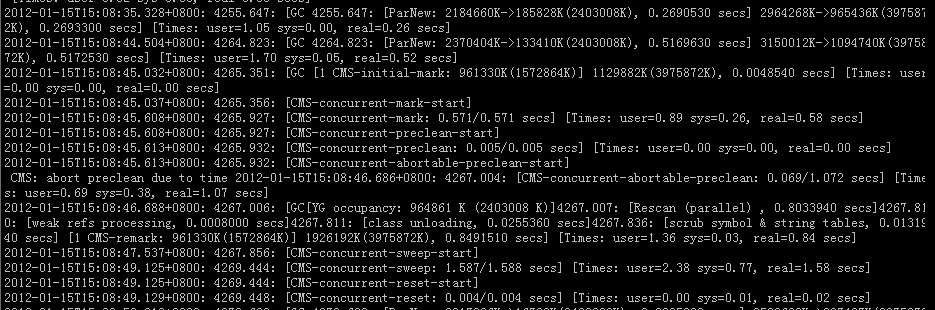
 1. 上图展示了truetime的api, truetime 用TTinterval来表示时间, 是一个不确定的时间间隔. 2. TTinterval 的端点是TTstamp. 3. TT.now 表示调用的绝对时间. time epoch 类似 unix的time(支持闰秒).4. 定义瞬间error bound为ε, 是间隔的一半宽度5. 平均error bound 为ε(带上划线)6. 一个event的绝对时间用Tabs(e), tt = TT.now(), tt.earlist <= Tabs(Enow) <= tt.latest. Enow 是调用event7. 使用gps 和原子钟作为truetime的参考, 因为他们有不同的失败模型. GPS参考源的脆弱性包括天线和接收器故障,本地无线电干扰,相关故障(例如,设计错误,如不正确的闰秒处理和欺骗),以及GPS系统停机。原子钟可能以与GPS和彼此无关的方式失败,并且由于频率错误,长时间可能会产生显著的漂移。8. 每个datacenter 有个time master, 每台机器上有个timeslave 后台进程. 大多数主服务器都有专用天线的GPS接收器;这些主服务器都被物理分隔开以减少天线故障、无线电干扰和欺骗的影响。剩余的主服务器(我们称之为Armageddon master)都配备了原子钟。一个原子钟并不那么昂贵:Armageddon master的成本与GPS主服务器的成本大致相当。所有主服务器的时间参考都定期互相对比。每个主服务器也会交叉检查其参考时间推进的速率与自己的本地时钟,并在存在大的偏差时剔除自己。在同步之间,Armageddon master会宣布一个慢慢增加的时间不确定性,这是从保守应用的最坏情况时钟漂移中得出的。GPS主服务器宣布的不确定性通常接近于零。9. 每个守护进程都会查询各种主服务器,以减少对任何一个主服务器错误的敏感性。其中一些是从附近的数据中心选择的GPS主服务器;其余的是来自较远数据中心的GPS主服务器,以及一些 Armageddon masters。守护进程应用Marzullo的算法的一个变体来检测和拒绝说谎者,并将本地机器的时钟与非说谎者同步。为了防止本地时钟出错,那些表现出频率偏差大于由组件规格和操作环境派生出的最坏情况界限的机器将被逐出。正确性取决于确保最坏情况界限得到执行。10. 在同步之间,守护进程会产生一个缓慢增加的时间不确定性。ε 是由保守地应用最坏情况的本地时钟漂移派生出来的。ε 还取决于timemaster的不确定性和与timemaster的通信延迟。在我们的生产环境中,ε 通常是时间的锯齿函数,每个轮询间隔从大约 1 到 7 毫秒变化。因此,ε 大部分时间都是 4 毫秒。守护进程的轮询间隔目前是 30 秒,当前应用的漂移率设置为每秒 200 微秒,这两者共同构成了从 0 到 6 毫秒的锯齿边界。剩下的 1 毫秒来自与时间主的通信延迟。在故障存在的情况下可能会偏离这个锯齿。例如,偶然的时间主不可用可能会导致数据中心范围内的 ε 增加。同样,过载的机器和网络连接可能会导致偶然的本地化 ε 峰值。由于 Spanner 可以等待不确定性,所以 ε 的变化不会影响正确性,但是如果 ε 增加太多,性能可能会降低。
1. 上图展示了truetime的api, truetime 用TTinterval来表示时间, 是一个不确定的时间间隔. 2. TTinterval 的端点是TTstamp. 3. TT.now 表示调用的绝对时间. time epoch 类似 unix的time(支持闰秒).4. 定义瞬间error bound为ε, 是间隔的一半宽度5. 平均error bound 为ε(带上划线)6. 一个event的绝对时间用Tabs(e), tt = TT.now(), tt.earlist <= Tabs(Enow) <= tt.latest. Enow 是调用event7. 使用gps 和原子钟作为truetime的参考, 因为他们有不同的失败模型. GPS参考源的脆弱性包括天线和接收器故障,本地无线电干扰,相关故障(例如,设计错误,如不正确的闰秒处理和欺骗),以及GPS系统停机。原子钟可能以与GPS和彼此无关的方式失败,并且由于频率错误,长时间可能会产生显著的漂移。8. 每个datacenter 有个time master, 每台机器上有个timeslave 后台进程. 大多数主服务器都有专用天线的GPS接收器;这些主服务器都被物理分隔开以减少天线故障、无线电干扰和欺骗的影响。剩余的主服务器(我们称之为Armageddon master)都配备了原子钟。一个原子钟并不那么昂贵:Armageddon master的成本与GPS主服务器的成本大致相当。所有主服务器的时间参考都定期互相对比。每个主服务器也会交叉检查其参考时间推进的速率与自己的本地时钟,并在存在大的偏差时剔除自己。在同步之间,Armageddon master会宣布一个慢慢增加的时间不确定性,这是从保守应用的最坏情况时钟漂移中得出的。GPS主服务器宣布的不确定性通常接近于零。9. 每个守护进程都会查询各种主服务器,以减少对任何一个主服务器错误的敏感性。其中一些是从附近的数据中心选择的GPS主服务器;其余的是来自较远数据中心的GPS主服务器,以及一些 Armageddon masters。守护进程应用Marzullo的算法的一个变体来检测和拒绝说谎者,并将本地机器的时钟与非说谎者同步。为了防止本地时钟出错,那些表现出频率偏差大于由组件规格和操作环境派生出的最坏情况界限的机器将被逐出。正确性取决于确保最坏情况界限得到执行。10. 在同步之间,守护进程会产生一个缓慢增加的时间不确定性。ε 是由保守地应用最坏情况的本地时钟漂移派生出来的。ε 还取决于timemaster的不确定性和与timemaster的通信延迟。在我们的生产环境中,ε 通常是时间的锯齿函数,每个轮询间隔从大约 1 到 7 毫秒变化。因此,ε 大部分时间都是 4 毫秒。守护进程的轮询间隔目前是 30 秒,当前应用的漂移率设置为每秒 200 微秒,这两者共同构成了从 0 到 6 毫秒的锯齿边界。剩下的 1 毫秒来自与时间主的通信延迟。在故障存在的情况下可能会偏离这个锯齿。例如,偶然的时间主不可用可能会导致数据中心范围内的 ε 增加。同样,过载的机器和网络连接可能会导致偶然的本地化 ε 峰值。由于 Spanner 可以等待不确定性,所以 ε 的变化不会影响正确性,但是如果 ε 增加太多,性能可能会降低。



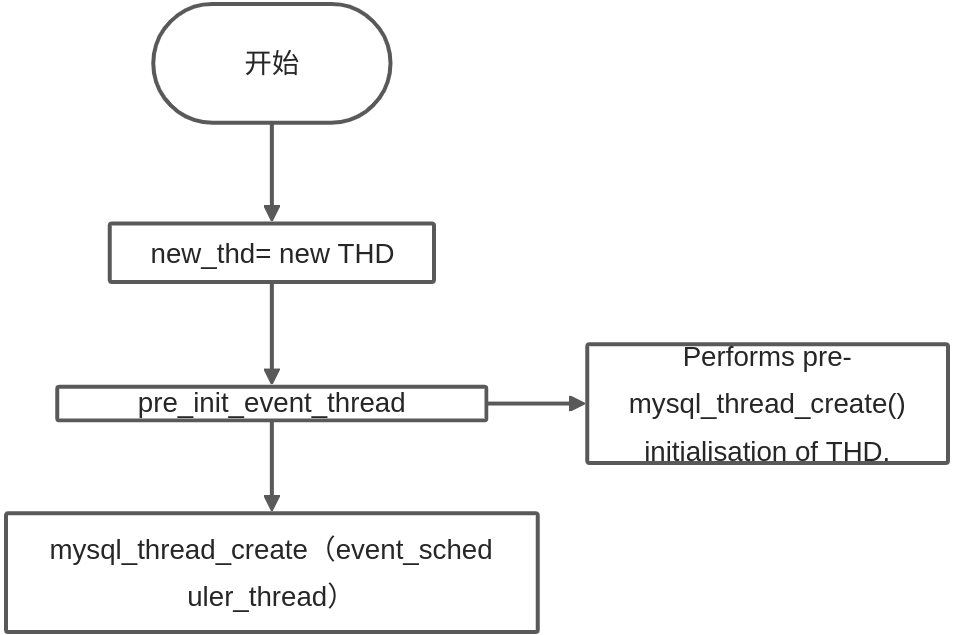
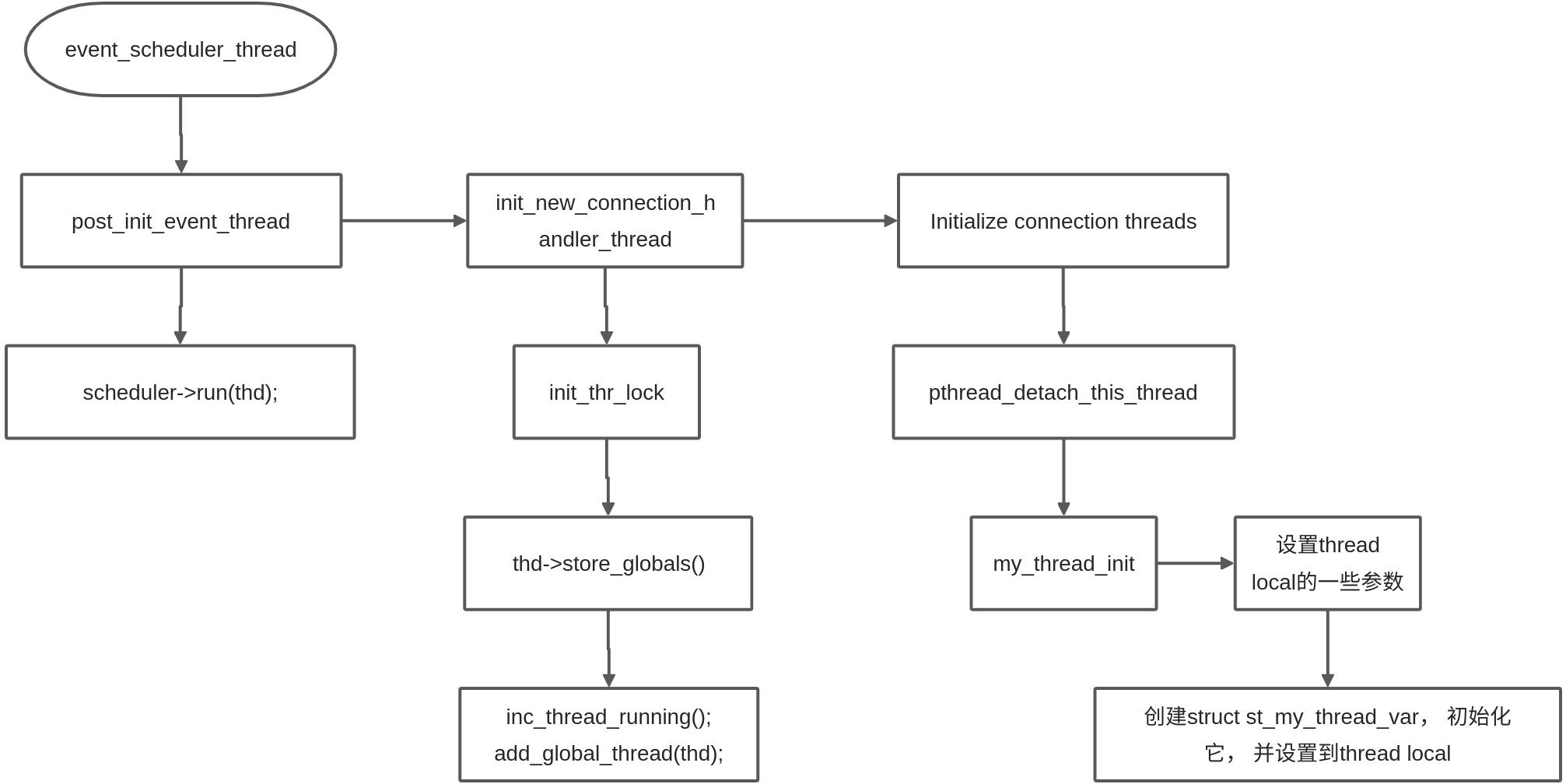
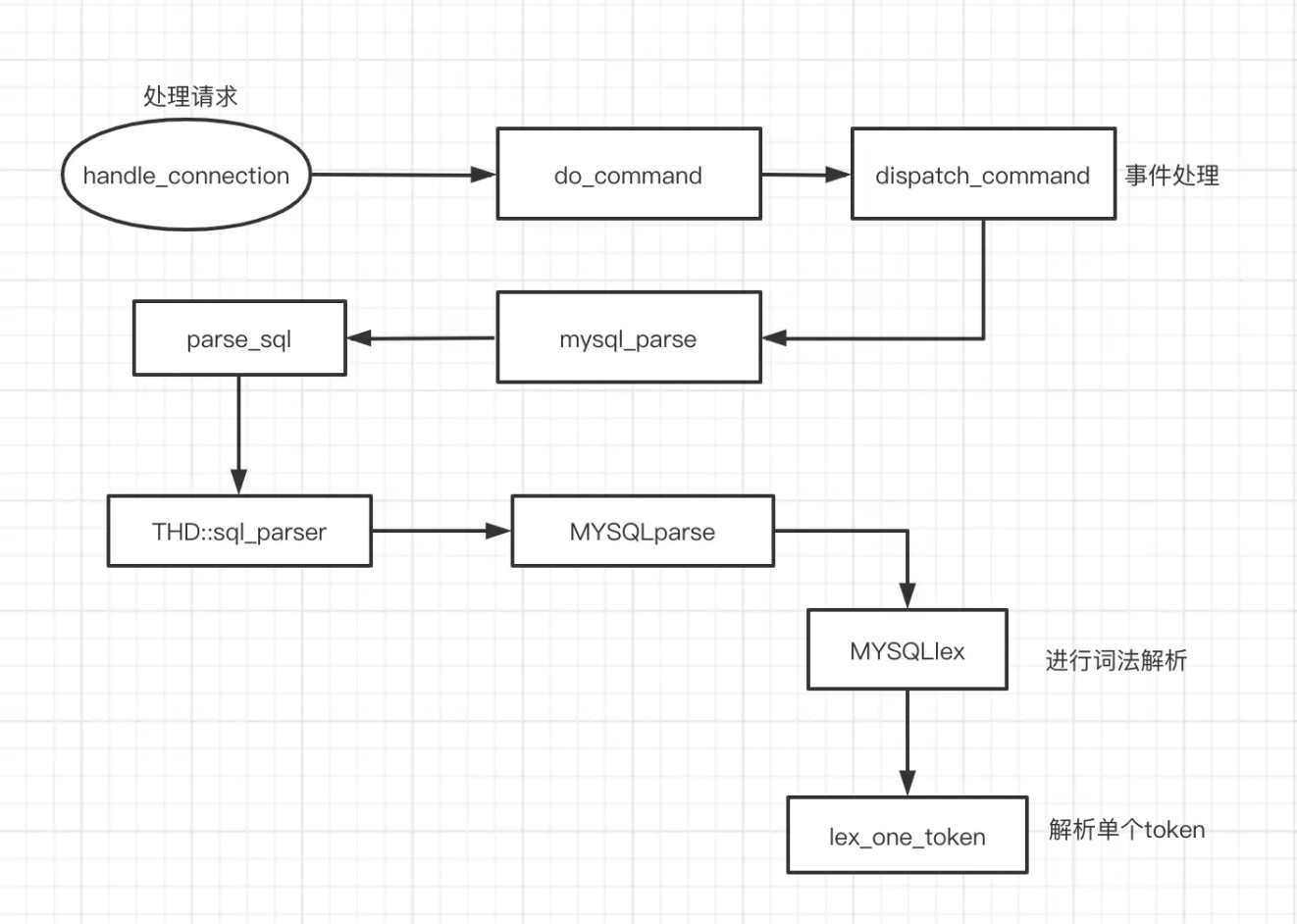
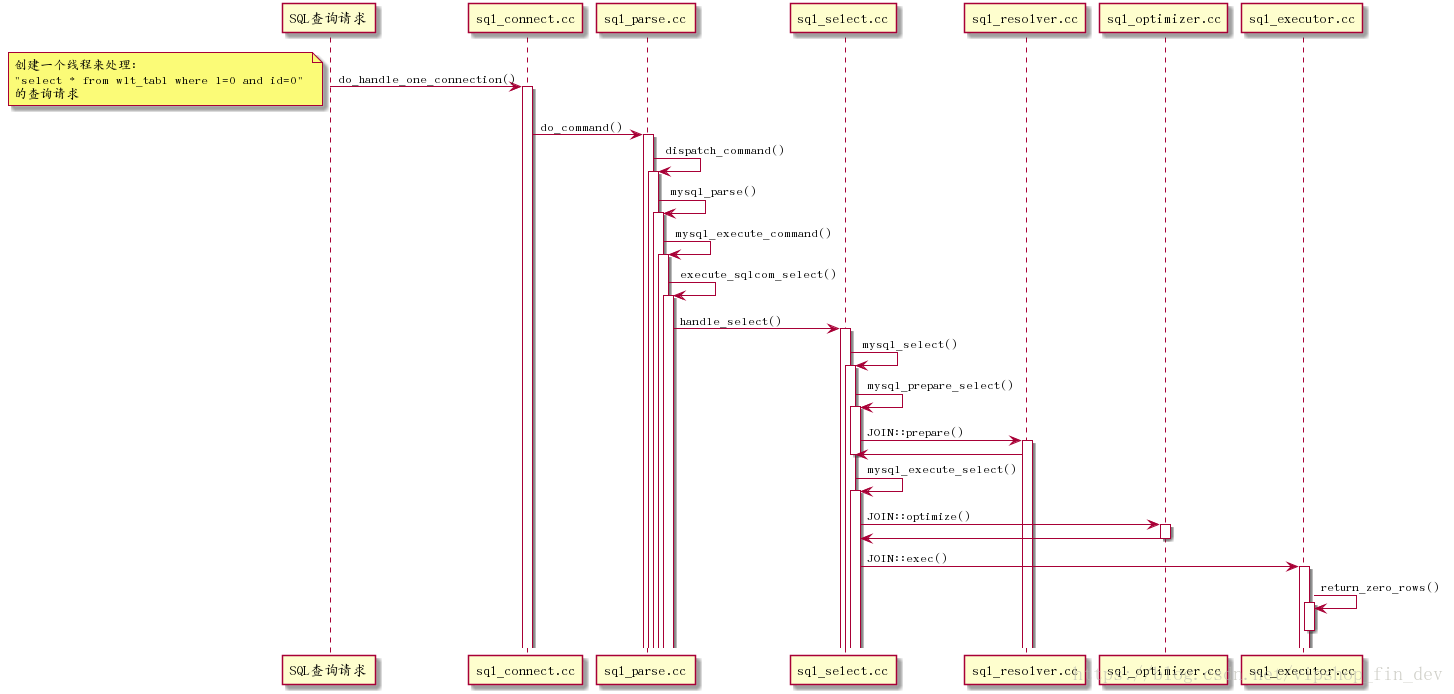

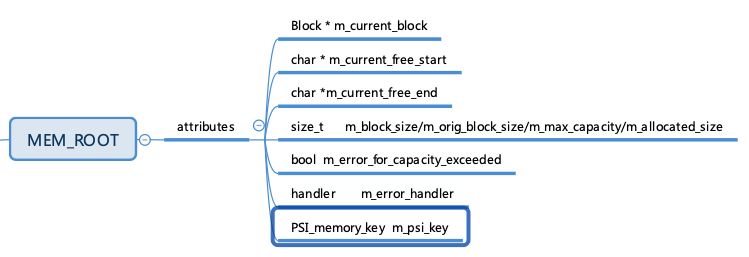
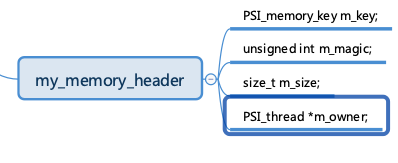









 、
、
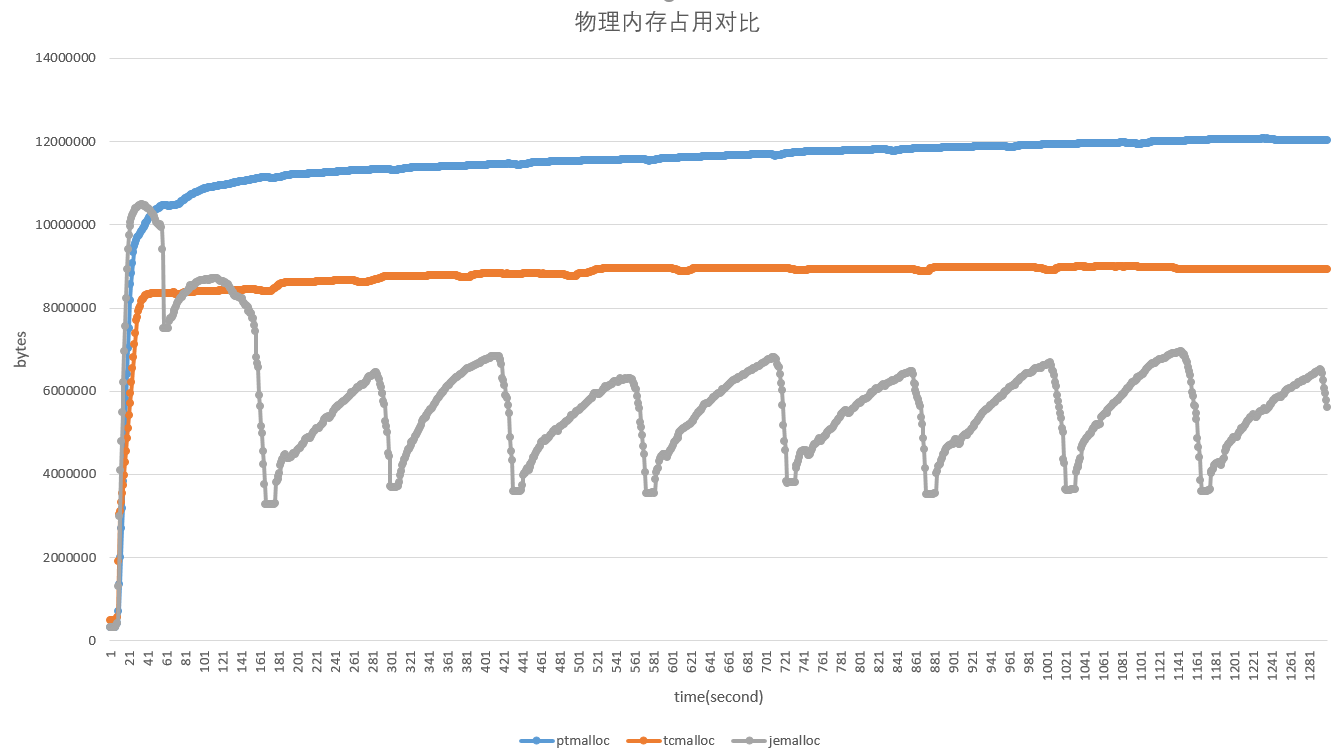
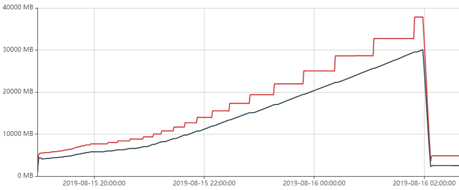
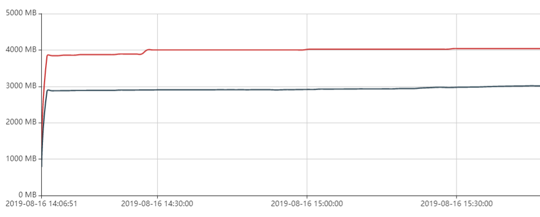







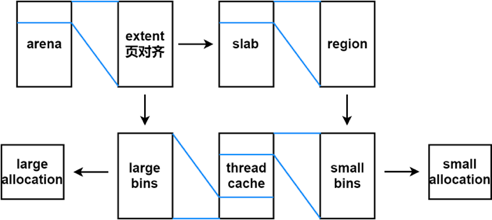





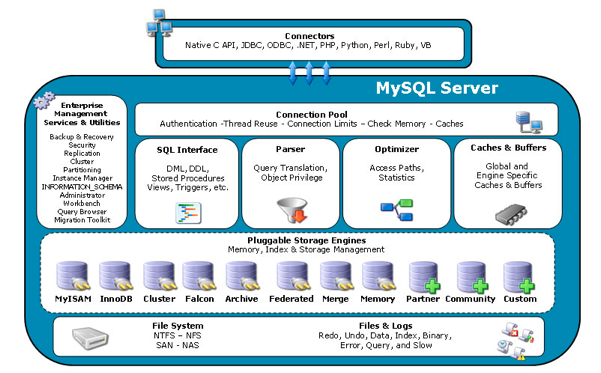
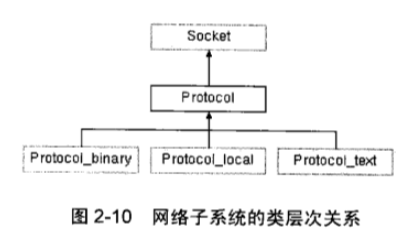
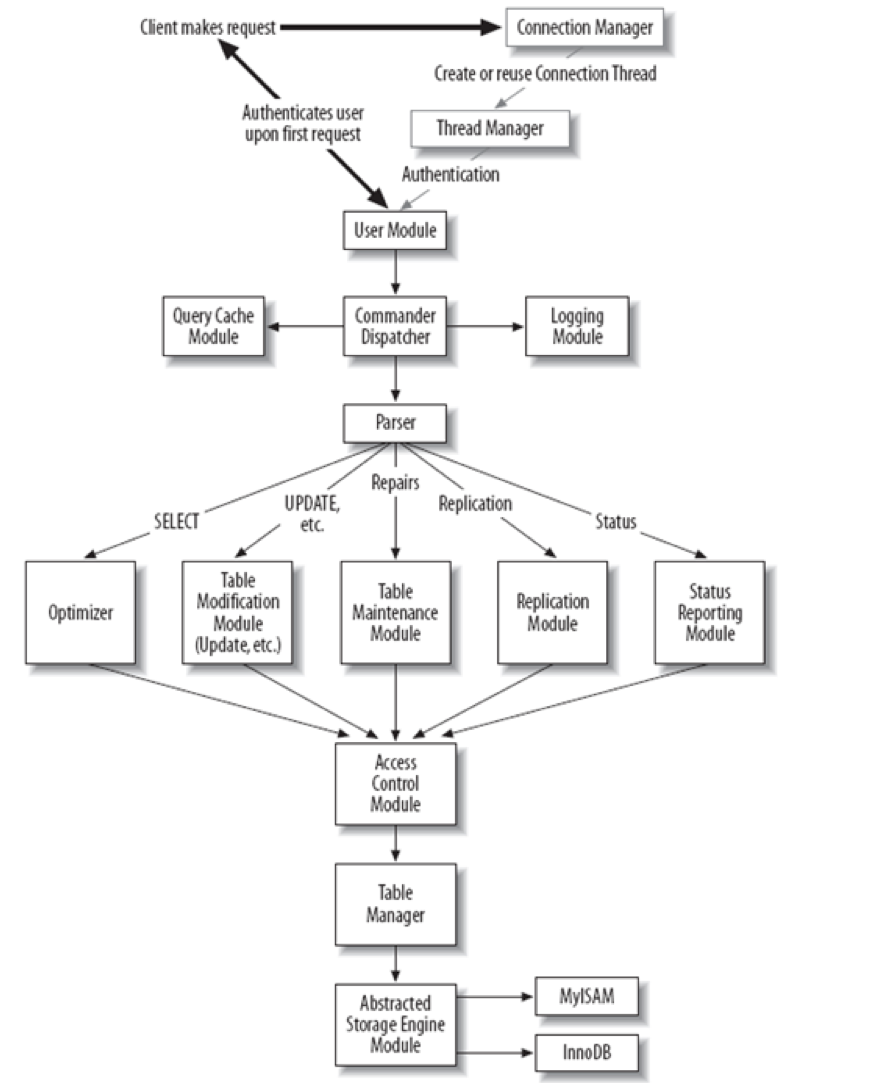
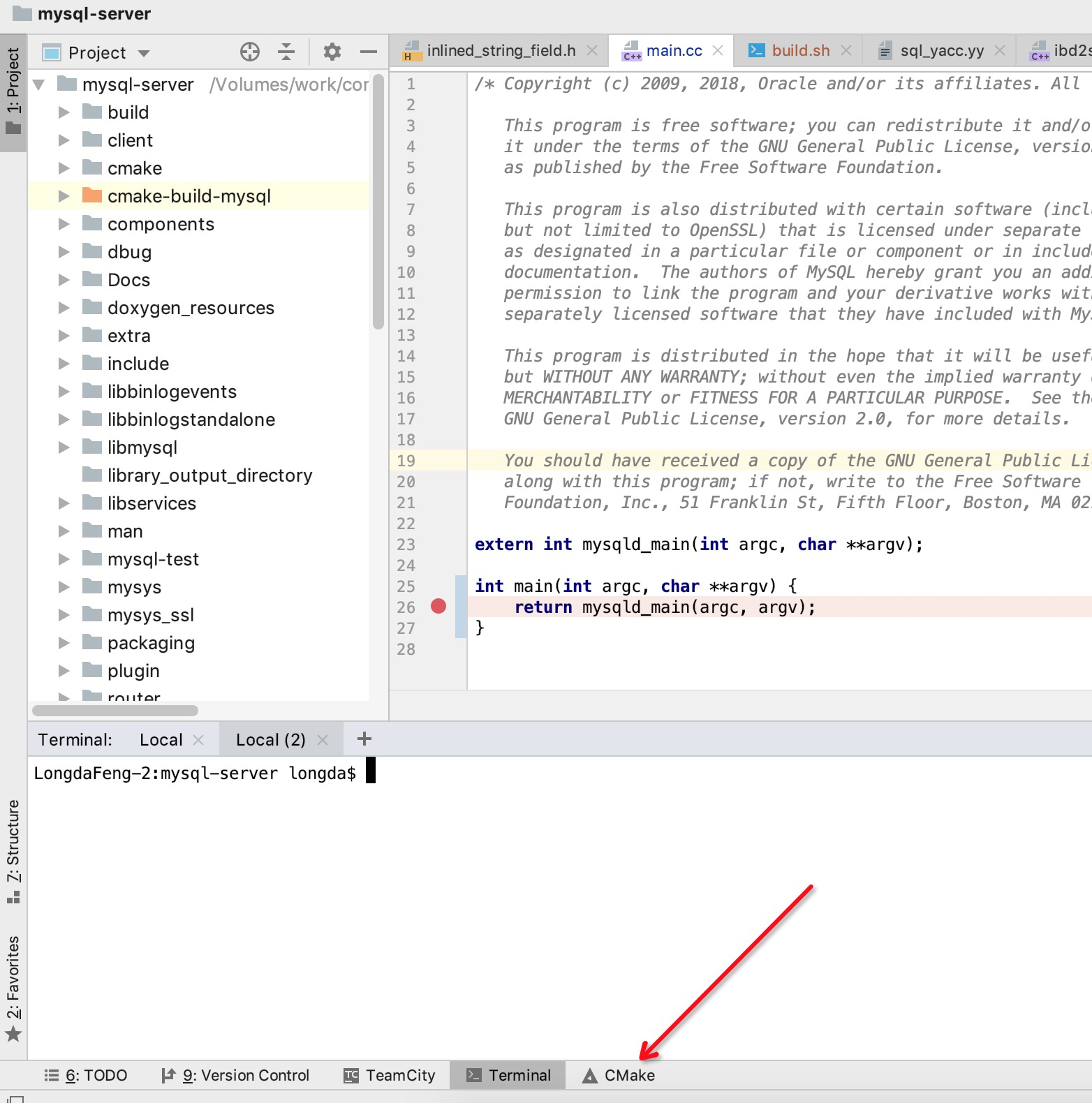
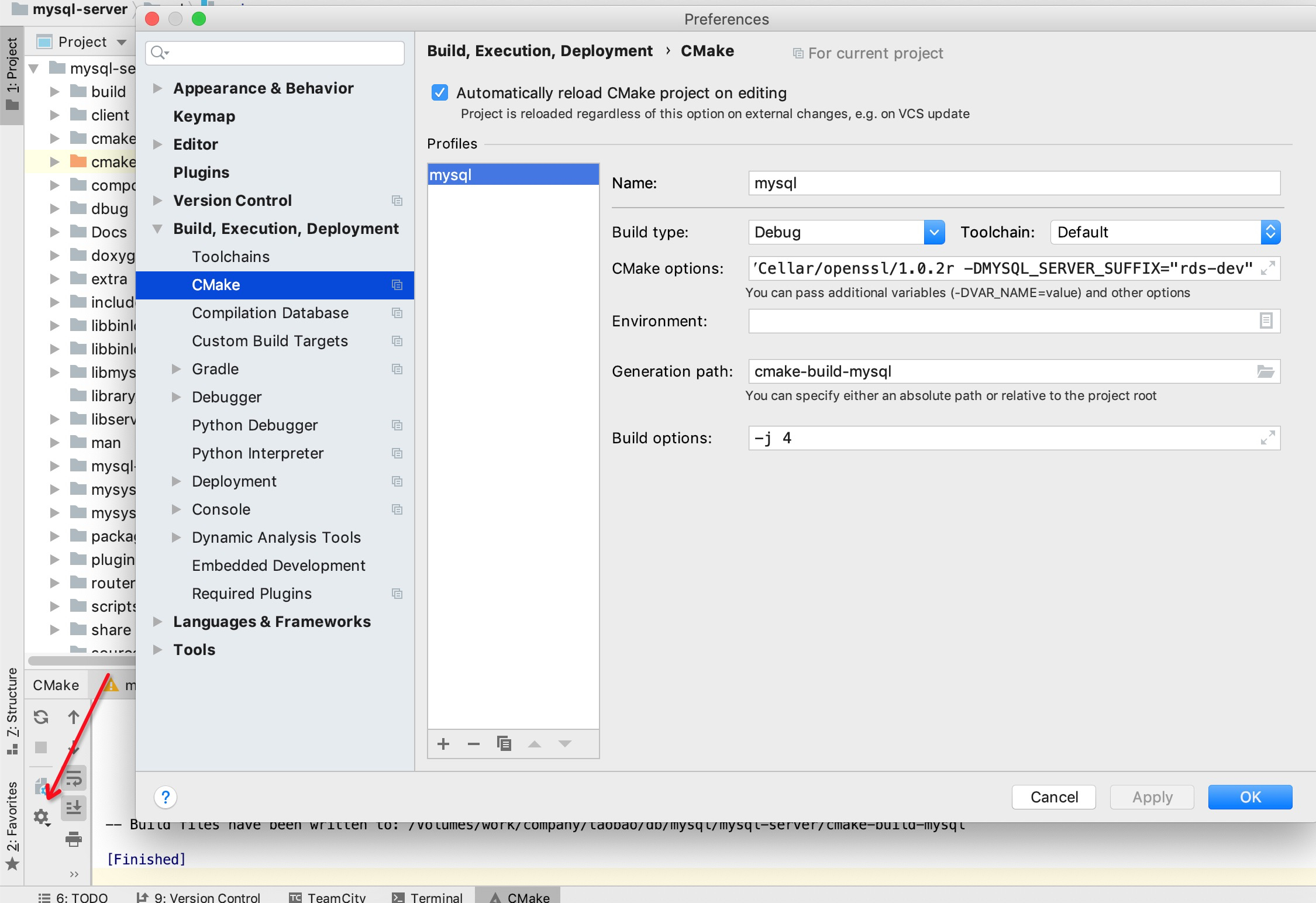
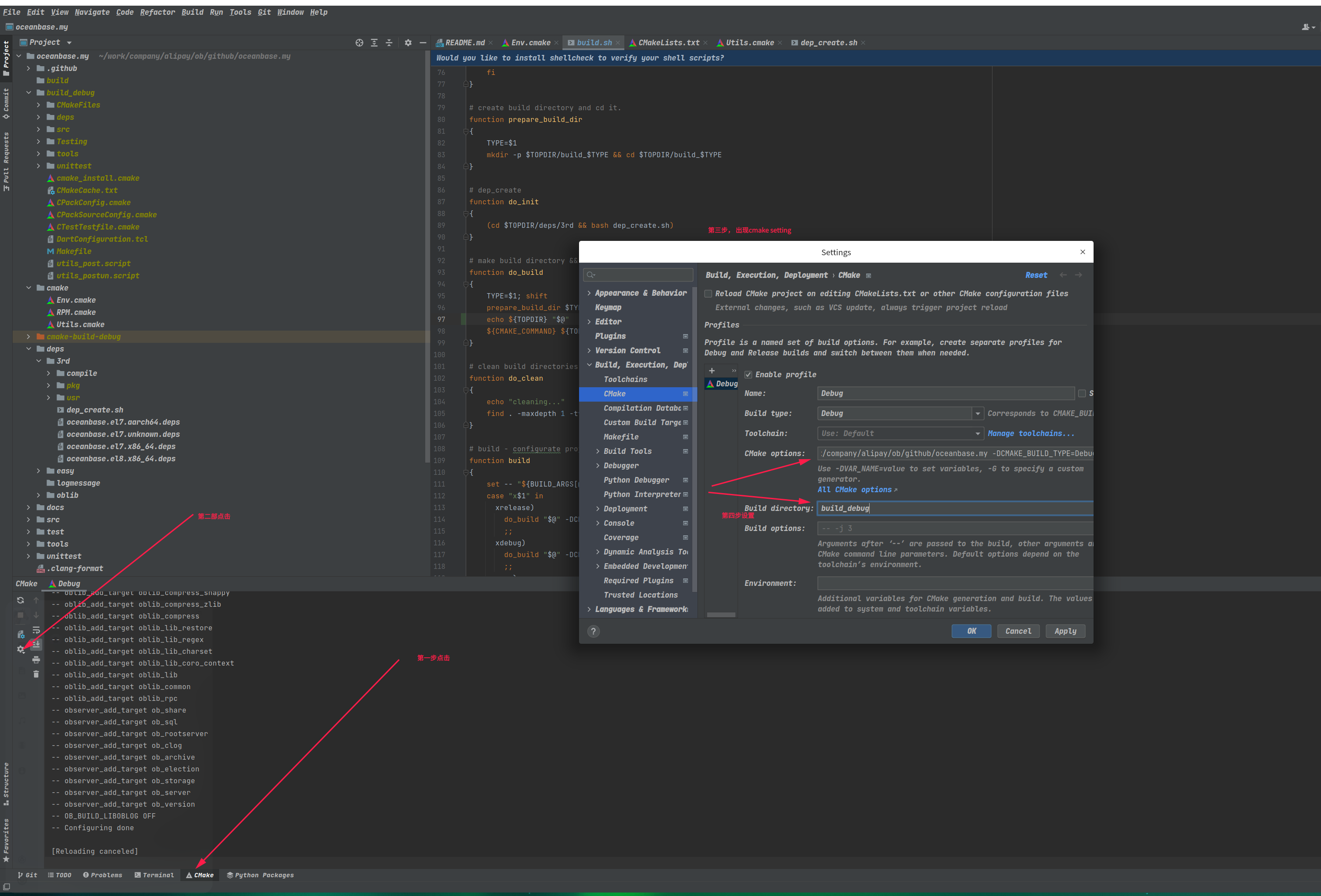
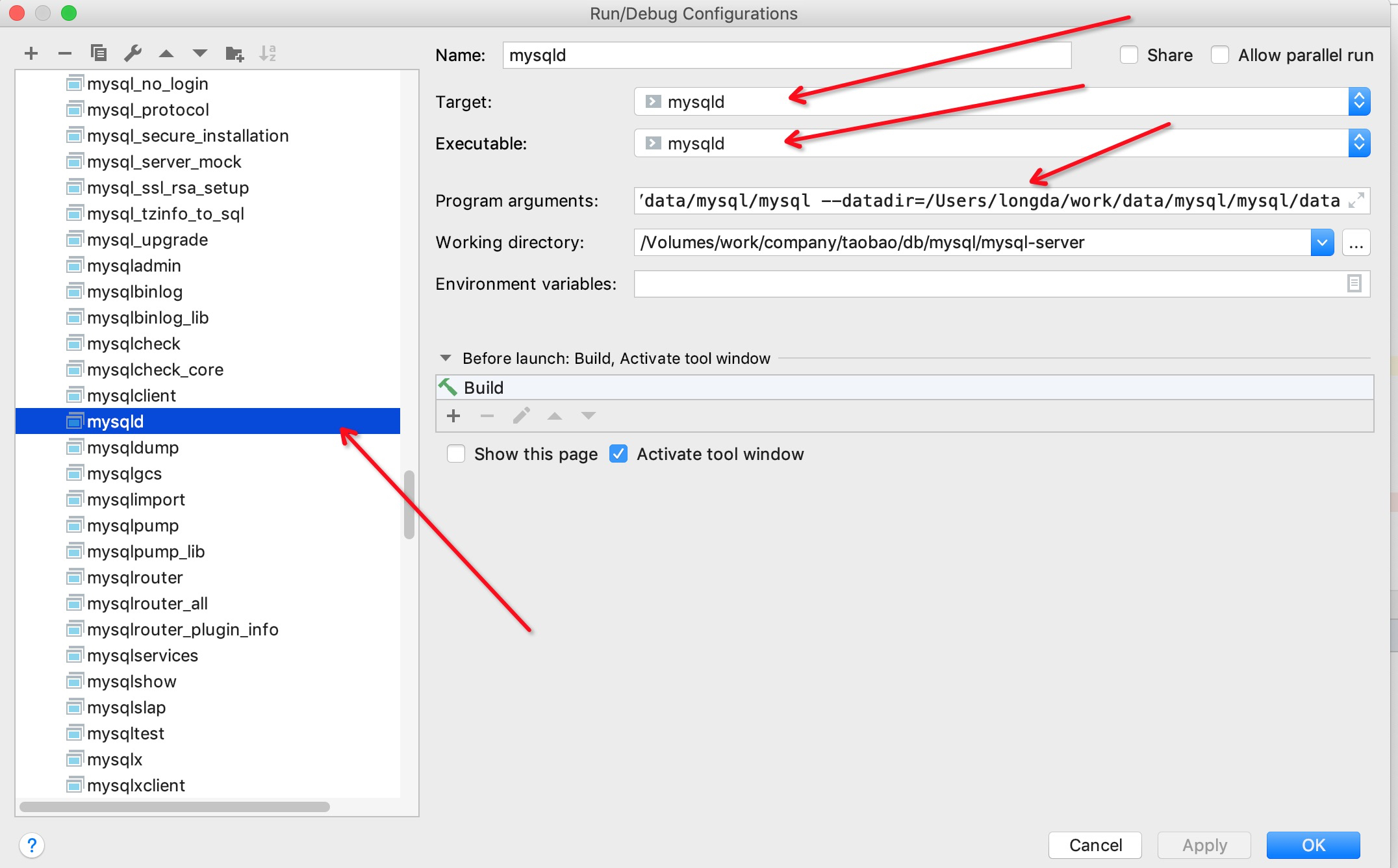 ## 编译:
## 编译:






















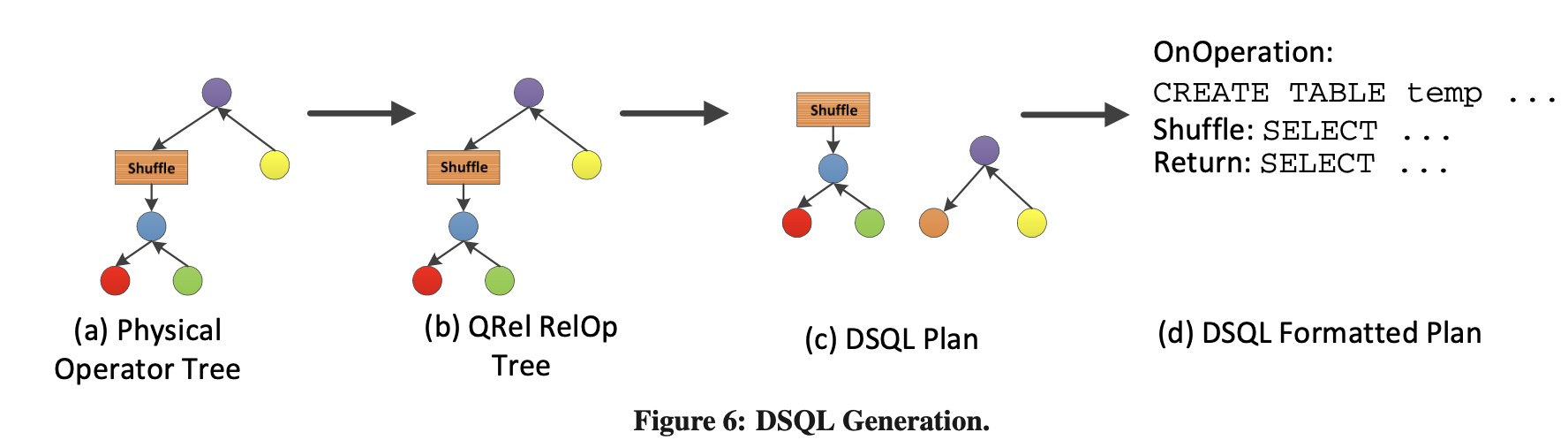

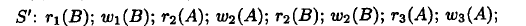

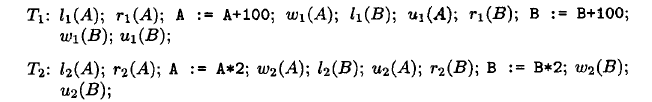







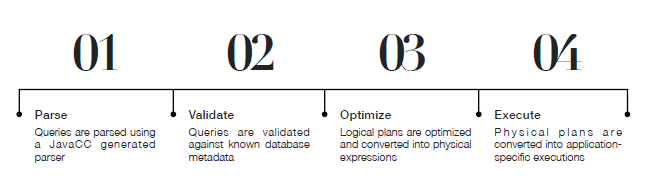
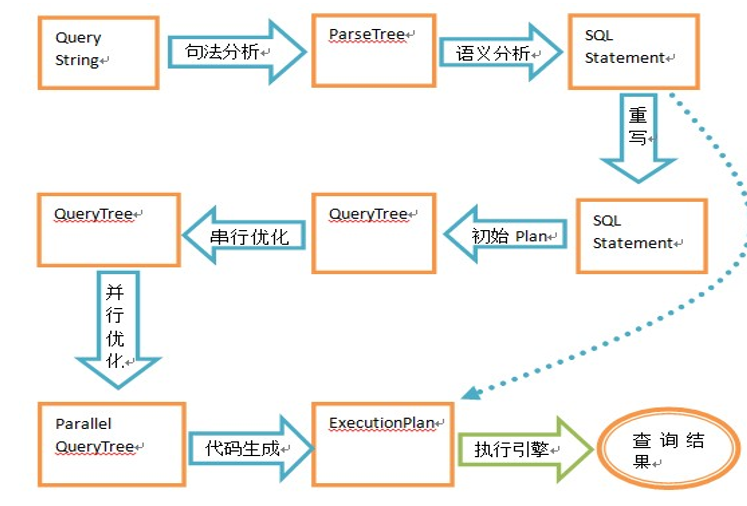
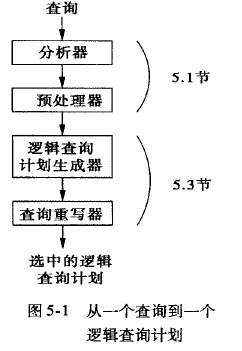

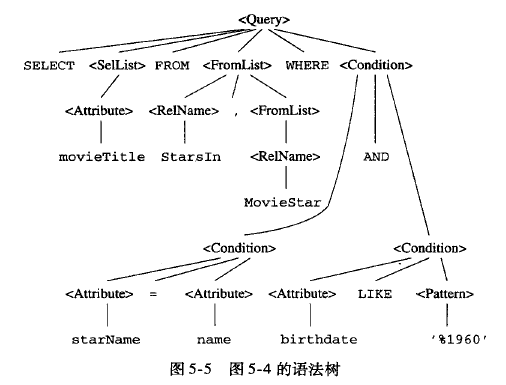



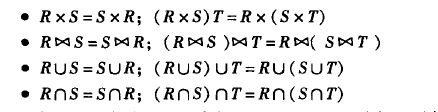
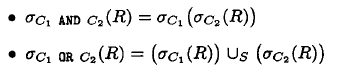
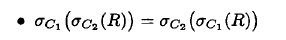
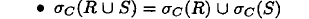
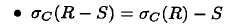 或者
或者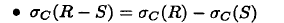
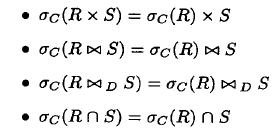
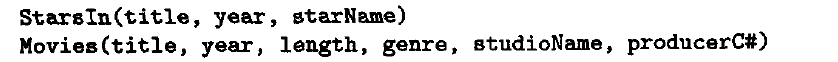
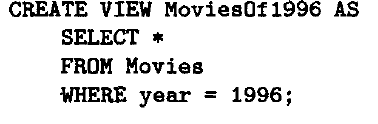
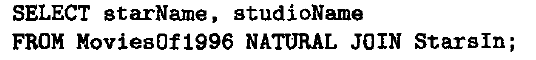
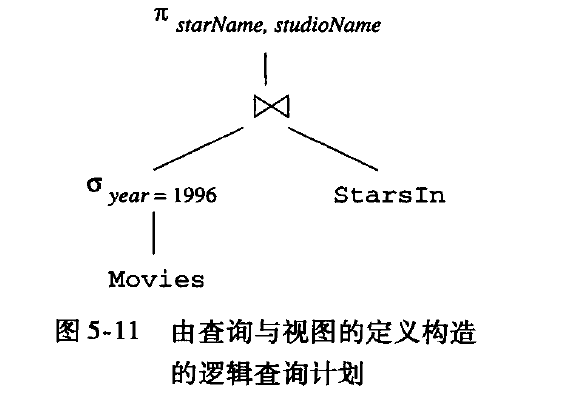
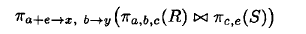
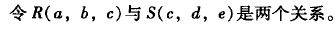
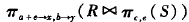

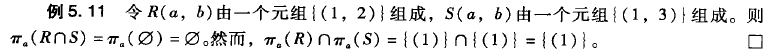

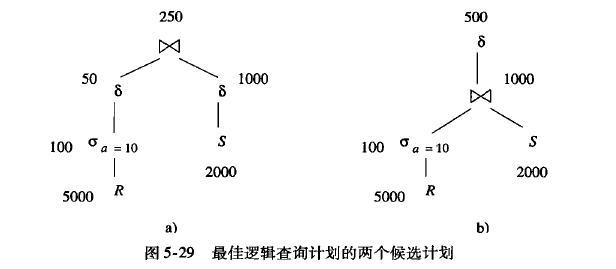
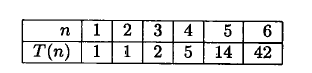
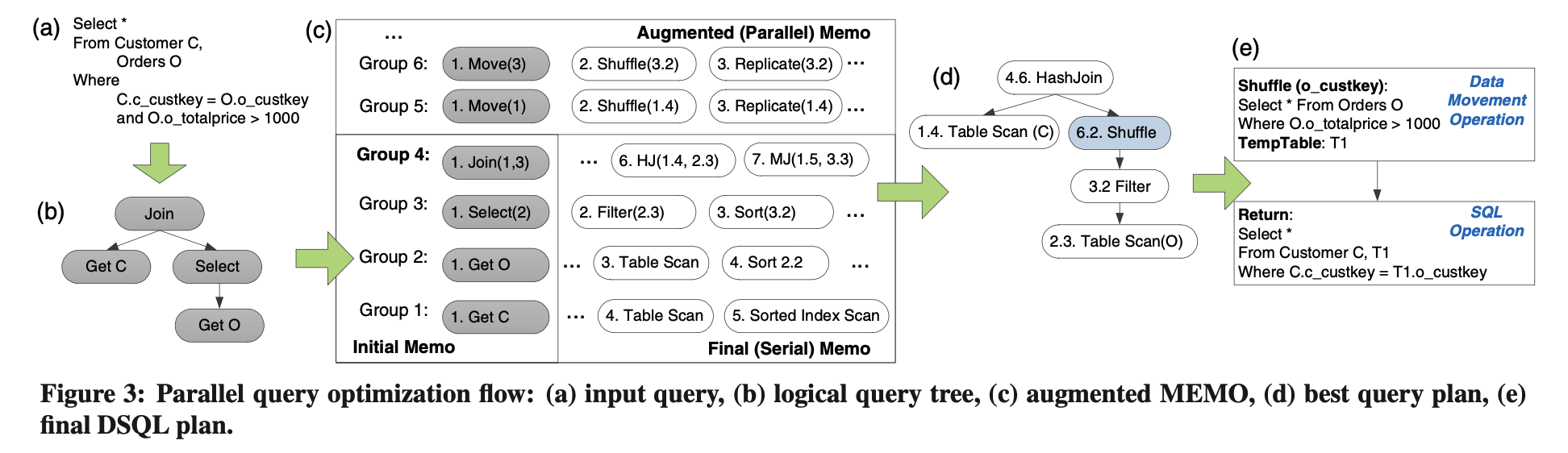
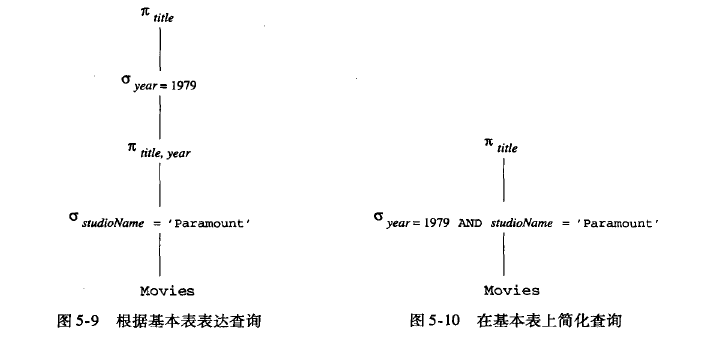
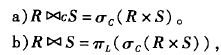 第一个表示基于C的自然连接
第一个表示基于C的自然连接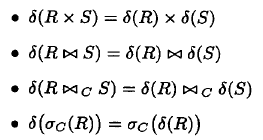
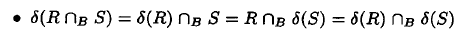

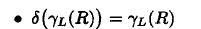

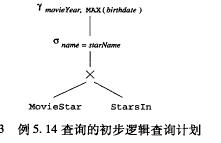
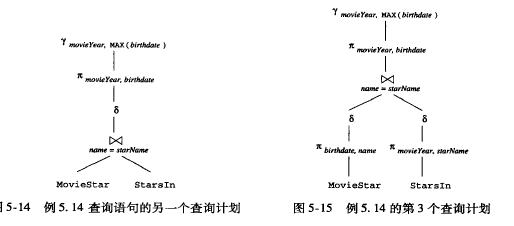
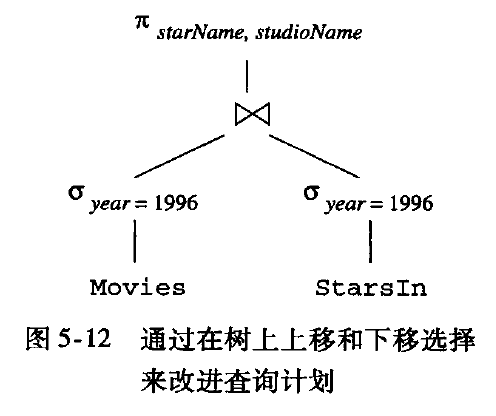
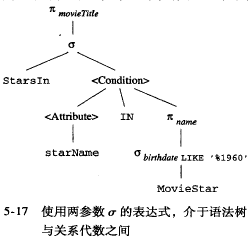 可以优化为
可以优化为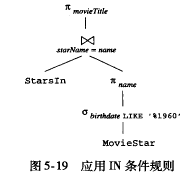
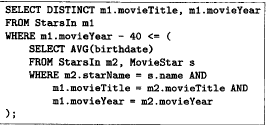
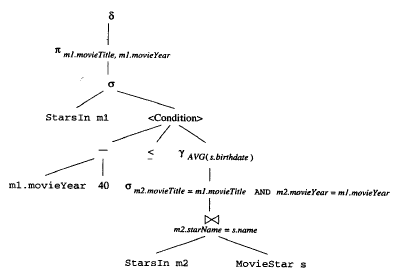
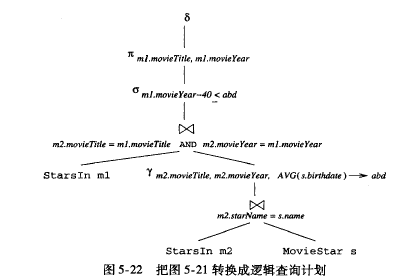
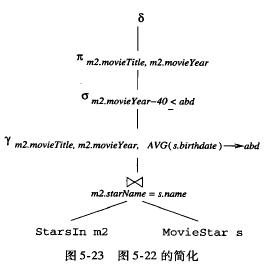
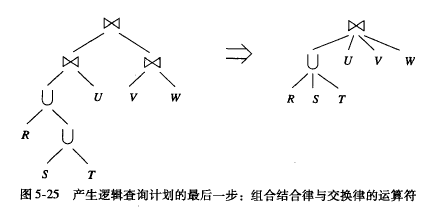
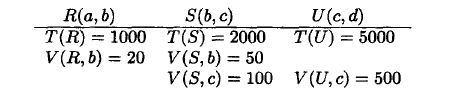
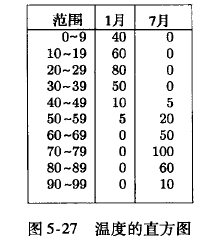

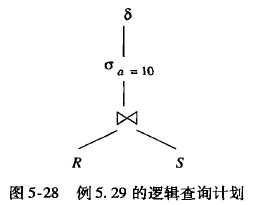 是否做下推,需要查看cost
是否做下推,需要查看cost